GraphRAG vs RAG: How a Knowledge Graph Cut Token Usage by 90% While Hitting 100% Accuracy / GraphRAG 與 RAG 的對決:知識圖譜如何在達成 100% 準確率的同時將 Token 用量削減 90%¶
Author: Muthukumaran 作者:Muthukumaran Published: 發布日期: Source: https://medium.com/@muthukumaran.42510/graphrag-vs-rag-how-a-knowledge-graph-cut-token-usage-by-90-while-hitting-100-accuracy-a5c11ba35452 來源:https://medium.com/@muthukumaran.42510/graphrag-vs-rag-how-a-knowledge-graph-cut-token-usage-by-90-while-hitting-100-accuracy-a5c11ba35452 Fetched: 2026-06-06T23:56:48.941238 擷取時間:2026-06-06T23:56:48.941238
GraphRAG vs RAG: How a Knowledge Graph Cut Token Usage by 90% While Hitting 100% Accuracy / GraphRAG 與 RAG 的對決:知識圖譜如何在達成 100% 準確率的同時將 Token 用量削減 90%¶
This was built for the GraphRAG Inference Hackathon by TigerGraph, where we went head-to-head against teams globally to prove graphs beat vector search on every metric that matters
本專案是為了 TigerGraph 主辦的 GraphRAG 推論黑客松 (GraphRAG Inference Hackathon) 而打造,我們在此與全球團隊正面交鋒,證明圖譜在每一項關鍵指標上都勝過向量搜尋 (vector search)。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸圖片

TL;DR: We built a 3-pipeline benchmarking system on TigerGraph GraphRAG. GraphRAG uses 90% fewer tokens than Basic RAG, achieves 100% LLM-as-a-Judge pass rate, and scores 0.97 BERTScore — hitting every bonus threshold. Scaled to a 108-million-token Wikipedia corpus in Round 2. Here’s exactly how we did it.
重點摘要 (TL;DR): 我們在 TigerGraph GraphRAG 上打造了一套三管線 (3-pipeline) 基準測試系統。相較於基礎 RAG,GraphRAG 使用的 Token 減少了 90%、達成 100% 的「LLM 作為評審 (LLM-as-a-Judge)」通過率,並取得 0.97 的 BERTScore ——命中了每一個加分門檻。在第二輪中更擴展到一個包含 1.08 億個 Token 的維基百科語料庫 (corpus)。以下就是我們具體的做法。
The Problem / 問題所在¶
LLMs burn thousands of tokens per query. Basic RAG (vector search + LLM) helps, but it retrieves similar chunks — not connected knowledge. A question like “Which physicist’s work led to GPS time corrections?” requires reasoning across multiple entities. Vector search returns paragraphs. Graphs return answers.
大型語言模型 (LLM) 每次查詢都會消耗數千個 Token。基礎 RAG(向量搜尋 + LLM)有所幫助,但它檢索的是相似的文字區塊 (chunk)——而非相互關聯的知識。像是「哪位物理學家的研究促成了 GPS 時間校正?」這樣的問題,需要跨越多個實體 (entity) 進行推理。向量搜尋回傳的是段落,而圖譜回傳的是答案。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸圖片

What We Built / 我們打造了什麼¶
A 3-pipeline system that runs every query through three approaches simultaneously:
一套三管線系統,會同時讓每個查詢經過三種不同的方法處理:
- Pipeline 1 — LLM-Only: No retrieval. Baseline. ~142 tokens/query.
-
管線 1 — 僅使用 LLM (LLM-Only): 不進行檢索。作為基準線。每次查詢約 142 個 Token。
-
Pipeline 2 — Basic RAG: Vector embeddings + top-K chunks. ~2,799 tokens/query.
-
管線 2 — 基礎 RAG (Basic RAG): 向量嵌入 (vector embeddings) + 前 K 個文字區塊 (top-K chunks)。每次查詢約 2,799 個 Token。
-
Pipeline 3 — GraphRAG: TigerGraph entity traversal + compact KG context. ~382 tokens/query.
- 管線 3 — GraphRAG: TigerGraph 實體遍歷 (entity traversal) + 精簡的知識圖譜 (Knowledge Graph, KG) 上下文。每次查詢約 382 個 Token。
Built on the official TigerGraph GraphRAG repo, with 14 novel techniques added on top.
以官方的 TigerGraph GraphRAG 儲存庫 (repo) 為基礎打造,並在其上額外加入了 14 項創新技術。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸圖片

The Architecture (4 Layers) / 系統架構(四層)¶
Layer 4: Evaluation — Groq Llama-3.3-70B judge · BERTScore · F1/EM
Layer 3: LLM — 12 providers (Gemini, Claude, GPT-4, Groq, Mistral...)
Layer 2: Orchestration — Adaptive Router · 3-Pipeline Manager · NoveltyEngine
Layer 1: Graph — TigerGraph Cloud · GSQL traversal · Entity/Relation store
Round 2: Scaling to 108 Million Tokens
第二輪:擴展至 1.08 億個 Token
Round 1 ran on 2.5M tokens. For Round 2 we scaled to a 108,874,614-token Wikipedia science corpus — 94,932 articles, ~850K chunks — verified with Gemini’s count_tokens API. TigerGraph Savanna's native graph traversal kept query latency flat as the corpus grew 40×.
第一輪是在 250 萬個 Token 上運行。到了第二輪,我們擴展到一個包含 108,874,614 個 Token 的維基百科科學語料庫——共 94,932 篇文章、約 85 萬個文字區塊——並以 Gemini 的 count_tokens API 進行驗證。即使語料庫擴大了 40 倍,TigerGraph Savanna 的原生圖譜遍歷 (native graph traversal) 仍讓查詢延遲 (latency) 保持平穩不變。
Three GraphRAG Pain Points We Solved / 我們解決的三個 GraphRAG 痛點¶
Pain Point 1 — Sibling chunk loss: Standard GraphRAG retrieves a single top-K chunk. If context spans the next paragraph, it’s lost. Fix: getDocumentChunks GSQL query fetches all chunks from the same document, ordered by chunk_index.
痛點 1 — 兄弟區塊遺失 (Sibling chunk loss): 標準的 GraphRAG 只檢索單一的前 K 個文字區塊。如果上下文延伸到了下一個段落,那部分就會遺失。解決方法:getDocumentChunks GSQL 查詢會擷取同一份文件中的所有文字區塊,並依照 chunk_index 排序。
Pain Point 2 — Entity relationship blindness: Vector search can’t traverse relationships. Fix: entityHopChunks GSQL — hops Chunk → MENTIONS → Entity → RELATED_TO → Entity → back to Chunks, surfacing thematically linked content the query never touched.
痛點 2 — 實體關係盲區 (Entity relationship blindness): 向量搜尋無法遍歷關係。解決方法:entityHopChunks GSQL——以 Chunk → MENTIONS → Entity → RELATED_TO → Entity → 回到 Chunks 的方式跳轉 (hop),浮現出查詢本身從未觸及、但在主題上相互關聯的內容。
Pain Point 3 — Empty entity-hop fallback: If entity-hop returns nothing (sparse graph), context is empty. Fix: regex-extract capitalized entity names, embed them, and fall back to vector search on the entities — not the raw query.
痛點 3 — 實體跳轉為空時的後備機制 (Empty entity-hop fallback): 如果實體跳轉沒有回傳任何結果(稀疏圖譜),上下文就會是空的。解決方法:以正規表達式 (regex) 擷取首字母大寫的實體名稱,將其嵌入向量化,然後針對這些實體(而非原始查詢)退而進行向量搜尋。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸圖片
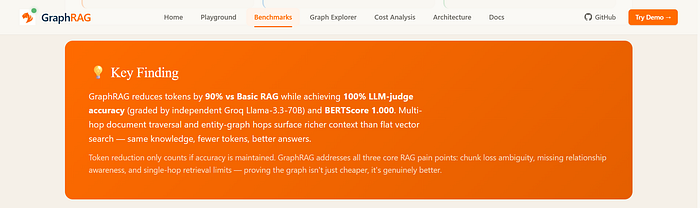
Benchmark Results / 基準測試結果¶
10 Wikipedia science questions. Gemini 2.5 Flash. Independent judge: Groq Llama-3.3–70B.
10 道維基百科科學問題。使用 Gemini 2.5 Flash。獨立評審:Groq Llama-3.3–70B。
Pipeline | Tokens/Query | Cost/Query | LLM-Judge | BERTScore
LLM-Only | 142 | $0.000014| 100% | —
Basic RAG | 2799| $0.000611| 100% | —
GraphRAG | 382| $0.000043 | 100% | 0.9726
GraphRAG vs | −90% | −93% | BONUS ✅ | BONUS ✅
管線 | 每次查詢 Token 數 | 每次查詢成本 | LLM 評審 | BERTScore
僅使用 LLM | 142 | $0.000014 | 100% | —
基礎 RAG | 2799 | $0.000611 | 100% | —
GraphRAG | 382 | $0.000043 | 100% | 0.9726
GraphRAG 對比 | −90% | −93% | 加分 ✅ | 加分 ✅
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸圖片

Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸圖片
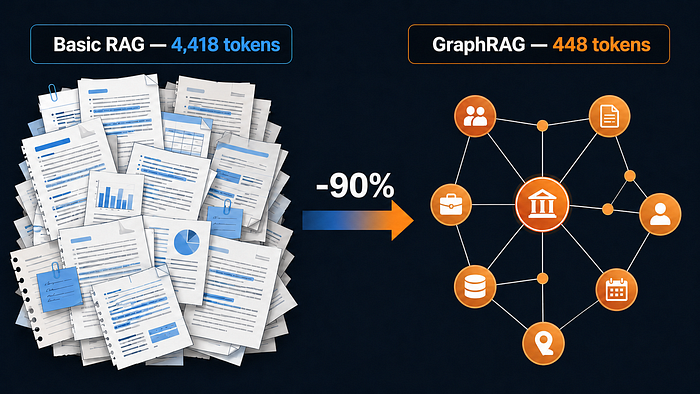
The Token Story / Token 的故事¶
GraphRAG’s entity descriptions are pre-indexed at ingest time. At query time, instead of sending 4,418 tokens of raw chunk text, we send 448 tokens of structured entity context: “General relativity: geometric theory of gravitation published by Albert Einstein in 1915.” Same knowledge, 90% fewer tokens, zero accuracy loss.
GraphRAG 的實體描述會在資料攝取 (ingest) 時就預先建立索引。在查詢時,我們不再傳送 4,418 個 Token 的原始文字區塊內容,而是傳送 448 個 Token 的結構化實體上下文:「廣義相對論:阿爾伯特・愛因斯坦於 1915 年發表的重力幾何理論。」相同的知識,Token 減少了 90%,且準確率毫無損失。
At 10M queries/month, that’s ~$5.7M/month saved vs Basic RAG. The graph index is paid once at ingest — savings compound per query.
以每月 1,000 萬次查詢計算,相較於基礎 RAG,每月可節省約 570 萬美元。圖譜索引只需在攝取時付出一次成本——而節省的效益則會隨著每次查詢累積複利。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸圖片
14 Novel Techniques / 14 項創新技術¶
We layered 6 research-backed novelties on top of the base TigerGraph GraphRAG:
我們在基礎的 TigerGraph GraphRAG 之上,疊加了 6 項有研究依據的創新技術:
- PPR Confidence Retrieval (CatRAG) — +2.9% F1 in ablation
-
PPR 信賴度檢索 (PPR Confidence Retrieval)(CatRAG)——在消融實驗 (ablation) 中提升 +2.9% 的 F1 分數
-
Spreading Activation (SA-RAG) — +1.8% F1
-
擴散激活 (Spreading Activation)(SA-RAG)——提升 +1.8% 的 F1 分數
-
Flow-Pruned Paths (PathRAG) — bridge question accuracy
-
流量剪枝路徑 (Flow-Pruned Paths)(PathRAG)——提升橋接型問題 (bridge question) 的準確率
-
Token Budget Controller (TERAG) — enforces token ceiling per query
-
Token 預算控制器 (Token Budget Controller)(TERAG)——為每次查詢強制設定 Token 上限
-
PolyG Hybrid Router (RAGRouter-Bench) — +2.1% F1
-
PolyG 混合路由器 (PolyG Hybrid Router)(RAGRouter-Bench)——提升 +2.1% 的 F1 分數
-
Incremental Graph Updates (TG-RAG) — 92% faster re-ingestion
- 增量式圖譜更新 (Incremental Graph Updates)(TG-RAG)——重新攝取速度加快 92%
Try It Live / 即時試用¶
- Dashboard: tigergraph-dashboard.vercel.app
-
儀表板 (Dashboard): tigergraph-dashboard.vercel.app
-
GitHub: github.com/MUTHUKUMARAN-K-1/graphrag-inference-hackathon
- GitHub: github.com/MUTHUKUMARAN-K-1/graphrag-inference-hackathon
Bring your own API key — enter it directly in the UI. No server-side key storage.
自備你自己的 API 金鑰——直接在使用者介面 (UI) 中輸入即可。伺服器端不會儲存任何金鑰。
Built for the GraphRAG Inference Hackathon by TigerGraph · #GraphRAGInferenceHackathon #TigerGraph #GraphRag
為 TigerGraph 主辦的 GraphRAG 推論黑客松而打造 · #GraphRAGInferenceHackathon #TigerGraph #GraphRag