Advanced RAG Techniques: an Illustrated Overview / 進階 RAG 技術:圖解總覽¶
Author: IVAN ILIN
Published:
Source: https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
Fetched: 2026-06-07T02:39:28.738845

Groningen, Martinitoren, where the article was composed in the peace of the Noorderplatsoen
荷蘭格羅寧根的馬丁尼塔 (Martinitoren),本文便是在 Noorderplatsoen 公園的寧靜中寫成的。
Advanced RAG Techniques: an Illustrated Overview / 進階 RAG 技術:圖解總覽¶
A comprehensive study of the advanced retrieval augmented generation techniques and algorithms, systemising various approaches. The article comes with a collection of links in my knowledge base referencing various implementations and studies mentioned. / 對進階檢索增強生成 (Retrieval Augmented Generation) 技術與演算法的全面研究,並系統化整理各種方法。本文附有我知識庫中的一系列連結,引用了文中提及的各種實作與研究。¶
Since the goal of the post is to make an overview & explanation of avaliable RAG algorithms and techniques, I won’t dive into implementations details in code, just referencing them and leaving it to the vast documentation & tutorials available.
由於本文的目標是對現有的 RAG 演算法與技術做一個總覽與解說,因此我不會深入探討程式碼的實作細節,只會引用它們,並將細節留給網路上大量現成的 文件與教學。
Intro / 簡介¶
If you are familiar with the RAG concept, please skip to the Advanced RAG part.
如果你已經熟悉 RAG 的概念,請直接跳到「進階 RAG」的部分。
Retrieval Augmented Generation, aka RAG, provides LLMs with the information retrieved from some data source to ground its generated answer on. Basically RAG is Search + LLM prompting, where you ask the model to answer the query provided the information found with the search algorithm as a context. Both the query and the retrieved context are injected into the prompt that is sent to the LLM.
檢索增強生成(Retrieval Augmented Generation,簡稱 RAG)會將從某些資料來源檢索到的資訊提供給大型語言模型 (LLM),以作為其生成答案的依據。基本上,RAG 就是「搜尋 + LLM 提示詞 (prompting)」,你要求模型在搜尋演算法找到的資訊作為脈絡 (context) 的前提下回答查詢。查詢與檢索到的脈絡都會被注入到傳送給 LLM 的提示詞中。
RAG is the most popular architecture of the LLM based systems in 2023. There are many products build almost solely on RAG — from Question Answering services combining web search engines with LLMs to hundreds of chat-with-your-data apps.
RAG 是 2023 年最受歡迎的 LLM 系統架構。有許多產品幾乎完全建構在 RAG 之上——從結合網路搜尋引擎與 LLM 的問答 (Question Answering) 服務,到數以百計的「與你的資料對話 (chat-with-your-data)」應用程式。
Even the vector search area got pumped by that hype although embedding based search engines were made with faiss back in 2019. Vector database startups like chroma, weavaite.io and pinecone have been built upon existing open source search indices — mainly faiss and nmslib — and added an extra storage for the input texts plus some other tooling lately.
就連向量搜尋 (vector search) 領域也被這股熱潮推動,儘管早在 2019 年就已用 faiss 打造出基於嵌入 (embedding) 的搜尋引擎。像 chroma、weavaite.io 和 pinecone 這類向量資料庫新創公司,都建構在既有的開源搜尋索引之上——主要是 faiss 和 nmslib——並近期額外加上了輸入文字的儲存功能以及一些其他工具。
There are two most prominent open source libraries for LLM-based pipelines & applications — LangChain and LlamaIndex, founded with a month difference in October and November 2022, respectfully, inspired by the ChatGPT launch and having gained massive adoption in 2023.
目前針對基於 LLM 的管線 (pipeline) 與應用,有兩個最著名的開源函式庫——LangChain 與 LlamaIndex,兩者分別於 2022 年 10 月與 11 月創立,相差一個月,受到 ChatGPT 發布的啟發,並在 2023 年獲得大量採用。
The purpose of this article is to systemise the key advanced RAG techniques with references to their implementations — mostly in the LlamaIndex — in order to facilitate other developers’ dive into the technology.
本文的目的是系統化整理關鍵的進階 RAG 技術,並附上其實作的參考連結(多數在 LlamaIndex 中),以協助其他開發者深入這項技術。
The problem is that most of the tutorials cherry-pick one or several techniques and explain in details how to implement them rather than decribing the full variety of the avaliable tools .
問題在於,大多數教學只挑選一兩種技術並詳細解釋如何實作它們,而非描述現有工具的完整多樣性。
Another thing is that both LlamaIndex and LangChain are amazing open source projects, developing at such a pace that their documentation is already thicker than a machine learning textbook in 2016.
另一點是,LlamaIndex 與 LangChain 都是了不起的開源專案,發展速度之快,使得它們的文件已經比 2016 年的機器學習教科書還要厚。
Naive RAG / 樸素 RAG¶
The starting point of the RAG pipeline in this article would be a corpus of text documents — we skip everything before that point, leaving it to the amazing open source data loaders connecting to any imaginable source from Youtube to Notion.
本文中 RAG 管線的起點將是一個文字文件語料庫 (corpus)——在此之前的一切我們都略過,留給那些連接到從 Youtube 到 Notion 等任何你想得到的來源的優秀開源資料載入器 (data loader)。
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
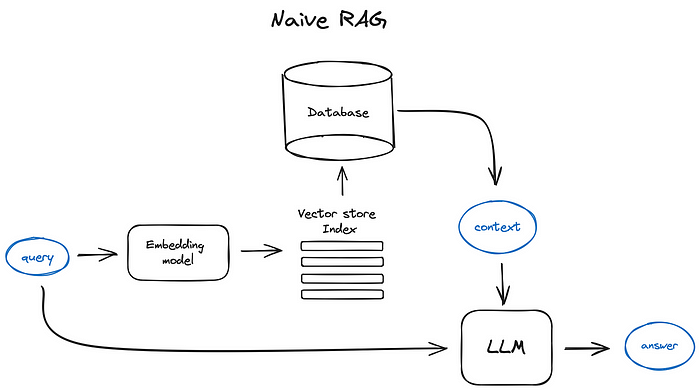
A scheme by author, as well all the schemes further in the text
由作者繪製的示意圖,以及後文所有的示意圖。
Vanilla RAG case in brief looks the following way: you split your texts into chunks, then you embed these chunks into vectors with some Transformer Encoder model, you put all those vectors into an index and finally you create a prompt for an LLM that tells the model to answers user’s query given the context we found on the search step.
In the runtime we vectorise user’s query with the same Encoder model and then execute search of this query vector against the index, find the top-k results, retrieve the corresponding text chunks from our database and feed them into the LLM prompt as context.
最基本的 RAG 案例簡而言之是這樣的:你將文字切分成區塊 (chunk),然後用某個 Transformer 編碼器 (Encoder) 模型將這些區塊嵌入成向量,把所有這些向量放進一個索引 (index),最後為 LLM 建立一個提示詞,告訴模型在我們於搜尋步驟中找到的脈絡下回答使用者的查詢。
在執行階段 (runtime),我們用同一個編碼器模型將使用者的查詢向量化,接著針對索引執行此查詢向量的搜尋,找出前 k 個 (top-k) 結果,從我們的資料庫中檢索對應的文字區塊,並將它們作為脈絡輸入到 LLM 的提示詞中。
The prompt can look like that:
提示詞可能長得像這樣:
an example of a RAG prompt
一個 RAG 提示詞的範例
Prompt engineering is the cheapest thing you can try to improve your RAG pipeline. Make sure you’ve checked a quite comprehensive OpenAI prompt engineering guide.
提示詞工程 (Prompt engineering) 是你能嘗試用來改善 RAG 管線的最廉價方法。請務必查閱相當全面的 OpenAI 提示詞工程指南。
Obviously despite OpenAI being the market leader as an LLM provider there is a number of alternatives such as Claude from Anthropic, recent trendy smaller but very capable models like Mixtral form Mistral, Phi-2 from Microsoft and many open source options like Llama2, OpenLLaMA, Falcon, so you have a choice of the brain for your RAG pipeline.
顯然,儘管 OpenAI 是 LLM 供應商的市場領導者,仍有不少替代選擇,例如 Anthropic 的 Claude、近期流行的較小但能力極強的模型如 Mistral 的 Mixtral、Microsoft 的 Phi-2,以及許多開源選項如 Llama2、OpenLLaMA、Falcon,因此你有多種「大腦」可供 RAG 管線選擇。
Advanced RAG / 進階 RAG¶
Now we’ll dive into the overview of the advanced RAG techniques.
Here is a scheme depicting core steps and algorithms involved.
Some logic loops and complex multistep agentic behaviours are omitted to keep the scheme readable.
現在我們將深入進階 RAG 技術的總覽。
以下是一張描繪所涉及核心步驟與演算法的示意圖。
為了保持示意圖的可讀性,省略了一些邏輯迴圈與複雜的多步驟代理 (agentic) 行為。
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
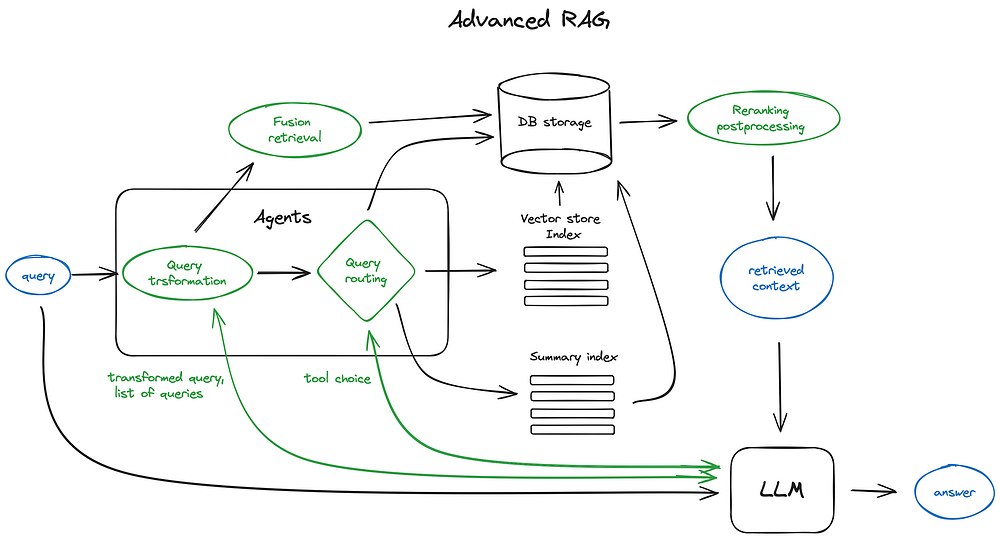
Some key components of an advanced RAG architecture. It’s more a choice of available instruments than a blueprint.
進階 RAG 架構的一些關鍵組件。這更像是現有工具的選擇集,而非一張藍圖。
The green elements on the scheme are the core RAG techniques discussed further, the blue ones are texts. Not all the advanced RAG ideas are easily visualised on a single scheme, for example, various context enlarging approaches are omitted — we’ll dive into that on the way.
示意圖中綠色的元素是後文將討論的核心 RAG 技術,藍色的則是文字。並非所有進階 RAG 的構想都能輕易在單一示意圖上呈現,例如,各種脈絡擴展的方法就被省略了——我們會在過程中逐步深入。
1. Chunking & vectorisation / 1. 切塊與向量化¶
First of all we want to create an index of vectors, representing our document contents and then in the runtime to search for the least cosine distance between all these vectors and the query vector which corresponds to the closest semantic meaning.
首先,我們希望建立一個代表文件內容的向量索引,然後在執行階段搜尋所有這些向量與查詢向量之間最小的餘弦距離 (cosine distance),也就是語意上最相近的內容。
1.1 Chunking
Transformer models have fixed input sequence length and even if the input context window is large, the vector of a sentence or a few better represents their semantic meaning than a vector averaged over a few pages of text (depends on the model too, but true in general), so chunk your data — split the initial documents in chunks of some size without loosing their meaning (splitting your text in sentences or in paragraphs, not cutting a single sentence in two parts). There are various text splitter implementations capable of this task.
1.1 切塊 (Chunking)
Transformer 模型有固定的輸入序列長度,而且即使輸入的脈絡視窗 (context window) 很大,一個句子或數個句子的向量也比對好幾頁文字取平均所得的向量更能代表其語意(這也取決於模型,但大致上成立),因此要對你的資料進行切塊——在不喪失其意義的前提下,將原始文件切分成某種大小的區塊(依句子或段落來切分文字,而非把一個句子切成兩半)。有各式各樣的文字切分器 (text splitter) 實作能勝任這項任務。
The size of the chunk is a parameter to think of — it depends on the embedding model you use and its capacity in tokens, standard transformer Encoder models like BERT-based Sentence Transformers take 512 tokens at most, OpenAI ada-002 is capable of handling longer sequences like 8191 tokens, but the compromise here is enough context for the LLM to reason upon vs specific enough text embedding in order to efficiently execute search upon. Here you can find a research illustrating chunk size selection concerns. In LlamaIndex this is covered by the NodeParser class with some advanced options as defining your own text splitter, metadata, nodes / chunks relations, etc.
區塊的大小是需要思量的一個參數——它取決於你所使用的嵌入模型及其以詞元 (token) 計的容量,像基於 BERT 的 Sentence Transformers 這類標準 Transformer 編碼器模型最多只能接受 512 個詞元,OpenAI ada-002 則能處理像 8191 個詞元這樣更長的序列,但這裡的取捨在於:要有足夠的脈絡讓 LLM 進行推理,與要有夠具體的文字嵌入以便有效執行搜尋,兩者之間的權衡。這裡你可以找到一份說明區塊大小選擇考量的研究。在 LlamaIndex 中,這由 NodeParser 類別涵蓋,並提供一些進階選項,例如定義你自己的文字切分器、元資料 (metadata)、節點 (node) 與區塊之間的關係等。
1.2 Vectorisation
The next step is to choose a model to embed our chunks — there are quite some options, I go with the search optimised models like bge-large or E5 embeddings family — just check the MTEB leaderboard for the latest updates.
1.2 向量化 (Vectorisation)
下一步是選擇一個用來嵌入我們區塊的模型——選項相當多,我會選擇針對搜尋最佳化的模型,如 bge-large 或 E5 嵌入家族——只需查看 MTEB 排行榜以取得最新資訊。
For an end2end implementation of the chunking & vectorisation step check an example of a full data ingestion pipeline in LlamaIndex.
關於切塊與向量化步驟的端到端 (end2end) 實作,請查看 LlamaIndex 中完整資料攝取管線 (data ingestion pipeline) 的範例。
2. Search index 2.1 Vector store index / 2. 搜尋索引 2.1 向量儲存索引¶
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
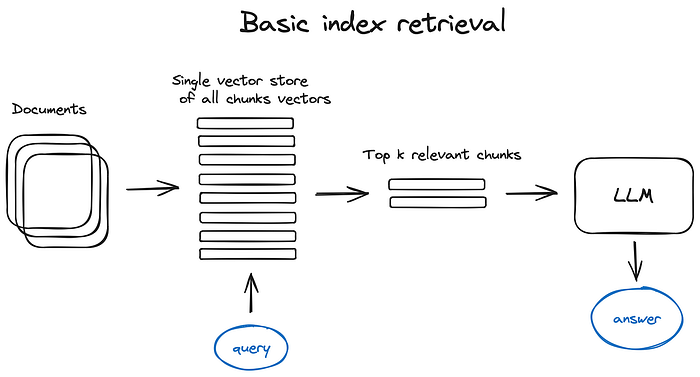
In this scheme and everywhere further in the text I omit the Encoder block and send our query straight to the index for the scheme simplicity. The query always gets vectorised first of course. Same with the top k cunks — index retrieves top k vectors, not chunks, but I replace them with chunks as fetching them is a trivial step.
在這張示意圖以及後文各處,為了簡化示意圖,我都省略了編碼器區塊,直接將查詢送進索引。當然,查詢一定會先被向量化。前 k 個區塊也是如此——索引檢索的是前 k 個向量,而非區塊,但我用區塊來取代它們,因為取得這些區塊只是一個微不足道的步驟。
The crucial part of the RAG pipeline is the search index, storing your vectorised content we got in the previous step. The most naive implementation uses a flat index — a brute force distance calculation between the query vector and all the chunks’ vectors.
RAG 管線的關鍵部分是搜尋索引,它儲存我們在上一步取得的向量化內容。最樸素的實作使用扁平索引 (flat index)——對查詢向量與所有區塊向量之間進行暴力法 (brute force) 的距離計算。
A proper search index, optimised for efficient retrieval on 10000+ elements scales is a vector index like faiss, nmslib or annoy, using some Approximate Nearest Neighbours implementation like clustring, trees or HNSW algorithm.
一個恰當的搜尋索引,針對在一萬個以上元素規模下的高效檢索做了最佳化,就是一個向量索引,如 faiss、nmslib 或 annoy,使用某種近似最近鄰 (Approximate Nearest Neighbours) 的實作,如分群 (clustering)、樹 (tree) 或 HNSW 演算法。
There are also managed solutions like OpenSearch or ElasticSearch and vector databases, taking care of the data ingestion pipeline described in step 1 under the hood, like Pinecone, Weaviate or Chroma.
也有像 OpenSearch 或 ElasticSearch 這類受管理 (managed) 的解決方案,以及向量資料庫,它們在底層處理了步驟 1 中所述的資料攝取管線,例如 Pinecone、Weaviate 或 Chroma。
Depending on your index choice, data and search needs you can also store metadata along with vectors and then use metadata filters to search for information within some dates or sources for example.
根據你的索引選擇、資料與搜尋需求,你也可以將元資料與向量一起儲存,然後使用元資料過濾器 (metadata filter) 來搜尋例如某些日期或來源範圍內的資訊。
LlamaIndex supports lots of vector store indices but there are also other simpler index implementations supported like list index, tree index, and keyword table index — we’ll talk about the latter in the Fusion retrieval part.
LlamaIndex 支援許多向量儲存索引,但也支援其他更簡單的索引實作,如列表索引 (list index)、樹索引 (tree index) 與關鍵字表索引 (keyword table index)——後者我們會在「融合檢索」部分談到。
2. 2 Hierarchical indices / 2.2 階層式索引¶
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
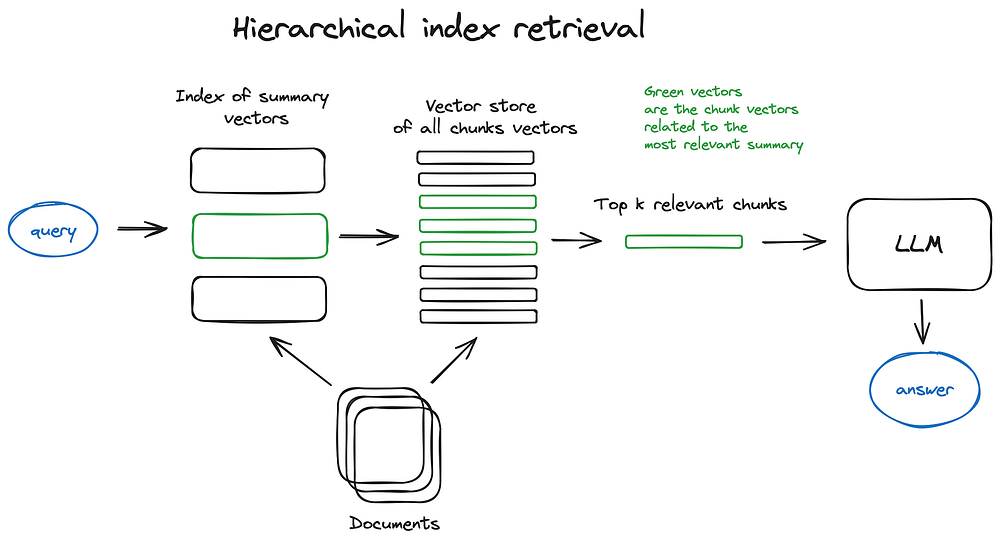
In case you have many documents to retrieve from, you need to be able to efficiently search inside them, find relevant information and synthesise it in a single answer with references to the sources. An efficient way to do that in case of a large database is to create two indices — one composed of summaries and the other one composed of document chunks, and to search in two steps, first filtering out the relevant docs by summaries and then searching just inside this relevant group.
如果你有許多文件需要檢索,你需要能夠在其中高效地搜尋、找到相關資訊,並將其綜合成一個帶有來源引用的單一答案。在大型資料庫的情況下,一個高效的做法是建立兩個索引——一個由摘要 (summary) 組成,另一個由文件區塊組成,並分兩步搜尋,首先透過摘要篩選出相關文件,然後只在這個相關群組內進行搜尋。
2.3 Hypothetical Questions and HyDE / 2.3 假設性問題與 HyDE¶
Another approach is to ask an LLM to generate a question for each chunk and embed these questions in vectors, at runtime performing query search against this index of question vectors (replacing chunks vectors with questions vectors in our index) and then after retrieval route to original text chunks and send them as the context for the LLM to get an answer.
This approach improves search quality due to a higher semantic similarity between query and hypothetical question compared to what we’d have for an actual chunk.
另一種方法是要求 LLM 為每個區塊生成一個問題,並將這些問題嵌入成向量,在執行階段針對這個問題向量的索引執行查詢搜尋(在我們的索引中以問題向量取代區塊向量),然後在檢索後導向原始文字區塊,並將它們作為脈絡送給 LLM 以取得答案。
相較於針對實際區塊所能得到的結果,這種方法因為查詢與假設性問題之間有更高的語意相似度而提升了搜尋品質。
There is also the reversed logic apporach called HyDE— you ask an LLM to generate a hypothetical response given the query and then use its vector along with the query vector to enhance search quality.
還有一種邏輯相反的方法稱為 HyDE——你要求 LLM 在給定查詢的情況下生成一個假設性的回應,然後將其向量與查詢向量一起使用,以提升搜尋品質。
2.4 Context enrichment / 2.4 脈絡豐富化¶
The concept here is to retrieve smaller chunks for better search quality, but add up surrounding context for LLM to reason upon.
There are two options — to expand context by sentences around the smaller retrieved chunk or to split documents recursively into a number of larger parent chunks, containing smaller child chunks.
這裡的概念是檢索較小的區塊以獲得更好的搜尋品質,但補上周圍的脈絡供 LLM 進行推理。
有兩種選擇——透過在較小的檢索區塊周圍補上句子來擴展脈絡,或是將文件遞迴地切分成若干個較大的父區塊 (parent chunk),每個父區塊包含較小的子區塊 (child chunk)。
2.4.1 Sentence Window Retrieval
In this scheme each sentence in a document is embedded separately which provides great accuracy of the query to context cosine distance search.
In order to better reason upon the found context after fetching the most relevant single sentence we extend the context window by k sentences before and after the retrieved sentence and then send this extended context to LLM.
2.4.1 句子視窗檢索 (Sentence Window Retrieval)
在這個方案中,文件裡的每個句子都被分別嵌入,這提供了查詢對脈絡的餘弦距離搜尋的極高準確度。
為了在取得最相關的單一句子後能更好地對找到的脈絡進行推理,我們將脈絡視窗向前與向後各擴展 k 個句子,然後將這個擴展後的脈絡送給 LLM。
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片

The green part is the sentence embedding found while search in index, and the whole black + green paragraph is fed to the LLM to enlarge its context while reasoning upon the provided query
綠色部分是在索引中搜尋時找到的句子嵌入,而整個黑色 + 綠色的段落會被輸入給 LLM,以在針對所提供的查詢進行推理時擴大其脈絡。
2.4.2 Auto-merging Retriever (aka Parent Document Retriever)
2.4.2 自動合併檢索器 (Auto-merging Retriever) (又稱 父文件檢索器 (Parent Document Retriever))
The idea here is pretty much similar to Sentence Window Retriever — to search for more granular pieces of information and then to extend the context window before feeding said context to an LLM for reasoning. Documents are split into smaller child chunks referring to larger parent chunks.
這裡的構想與句子視窗檢索器十分相似——搜尋更細粒度的資訊片段,然後在將該脈絡輸入給 LLM 進行推理之前擴展脈絡視窗。文件被切分成較小的子區塊,這些子區塊指向較大的父區塊。
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
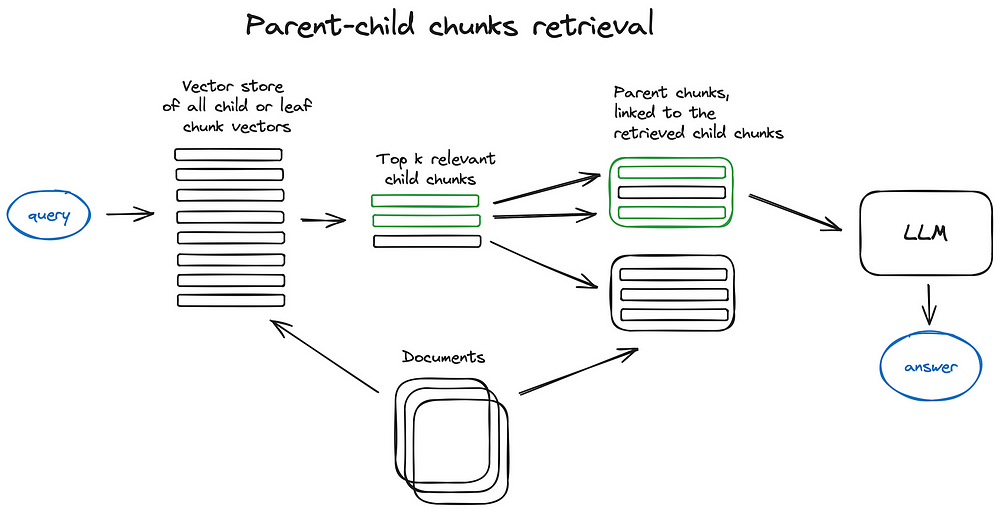
Documents are splitted into an hierarchy of chunks and then the smallest leaf chunks are sent to index. At the retrieval time we retrieve k leaf chunks, and if there is n chunks referring to the same parent chunk, we replace them with this parent chunk and send it to LLM for answer generation.
文件被切分成一個區塊的階層結構,然後最小的葉區塊 (leaf chunk) 被送進索引。在檢索時我們檢索 k 個葉區塊,如果有 n 個區塊指向同一個父區塊,我們就用這個父區塊取代它們,並將其送給 LLM 以生成答案。
Fetch smaller chunks during retrieval first, then if more than n chunks in top k retrieved chunks are linked to the same parent node (larger chunk), we replace the context fed to the LLM by this parent node — works like auto merging a few retrieved chunks into a larger parent chunk, hence the method name. Just to note — search is performed just within the child nodes index. Check the LlamaIndex tutorial on Recursive Retriever + Node References for a deeper dive.
在檢索時先取得較小的區塊,接著如果前 k 個檢索到的區塊中有超過 n 個區塊連結到同一個父節點(較大的區塊),我們就用這個父節點取代輸入給 LLM 的脈絡——其運作方式就像把幾個檢索到的區塊自動合併成一個較大的父區塊,方法名稱即源於此。要注意的是——搜尋只在子節點索引內執行。如需更深入的探討,請查看 LlamaIndex 關於遞迴檢索器 + 節點參照 (Recursive Retriever + Node References) 的教學。
2.5 Fusion retrieval or hybrid search / 2.5 融合檢索或混合搜尋¶
A relatively old idea that you could take the best from both worlds — keyword-based old school search — sparse retrieval algorithms like tf-idf or search industry standard BM25 — and modern semantic or vector search and combine it in one retrieval result.
The only trick here is to properly combine the retrieved results with different similarity scores — this problem is usually solved with the help of the Reciprocal Rank Fusion algorithm, reranking the retrieved results for the final output.
一個相對老的構想是:你可以兼採兩者之長——基於關鍵字的老派搜尋——稀疏檢索 (sparse retrieval) 演算法如 tf-idf 或搜尋業界標準 BM25——以及現代的語意搜尋或向量搜尋,並將其結合成一個檢索結果。
這裡唯一的訣竅是要妥善地結合具有不同相似度分數的檢索結果——這個問題通常借助倒數排名融合 (Reciprocal Rank Fusion) 演算法來解決,它會對檢索結果重新排序 (rerank) 以產生最終輸出。
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
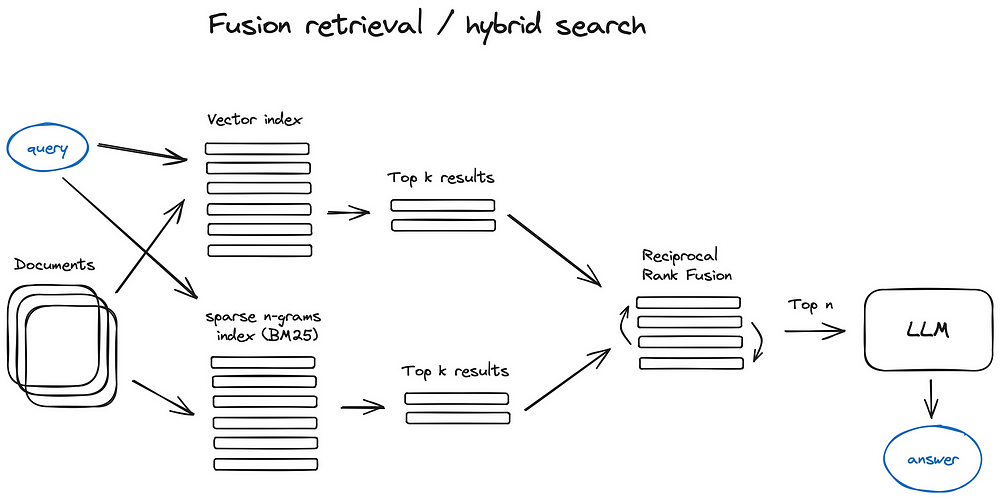
In LangChain this is implemented in the Ensemble Retriever class, combining a list of retrievers you define, for example a faiss vector index and a BM25 based retriever and using RRF for reranking.
在 LangChain 中,這透過 Ensemble Retriever 類別實作,結合你所定義的一系列檢索器,例如一個 faiss 向量索引與一個基於 BM25 的檢索器,並使用 RRF 進行重新排序。
In LlamaIndex this is done in a pretty similar fashion.
在 LlamaIndex 中,這也以相當類似的方式完成。
Hybrid or fusion search usually provides better retrieval results as two complementary search algorithms are combined, taking into account both semantic similarity and keyword matching between the query and the stored documents.
混合或融合搜尋通常能提供更好的檢索結果,因為結合了兩種互補的搜尋演算法,同時考量了查詢與所儲存文件之間的語意相似度與關鍵字匹配。
3. Reranking & filtering / 3. 重新排序與過濾¶
So we got our retrieval results with any of the algorithms described above, now it is time to refine them through filtering, re-ranking or some transformation. In LlamaIndex there is a variety of available Postprocessors, filtering out results based on similarity score, keywords, metadata or reranking them with other models like an LLM,
sentence-transformer cross-encoder, Cohere reranking endpoint
or based on metadata like date recency — basically, all you could imagine.
於是我們用上述任一演算法取得了檢索結果,現在該透過過濾、重新排序或某些轉換來精煉它們了。在 LlamaIndex 中有各式各樣可用的後處理器 (Postprocessor),根據相似度分數、關鍵字、元資料來過濾結果,或用其他模型對它們重新排序,例如用 LLM、
sentence-transformer 交叉編碼器 (cross-encoder)、Cohere 的重新排序 端點 (endpoint),
或根據像日期新近度這類元資料——基本上,你能想到的都有。
This is the final step before feeding our retrieved context to LLM in order to get the resulting answer.
這是將我們檢索到的脈絡輸入給 LLM 以取得最終答案之前的最後一步。
Now it is time to get to the more sophisticated RAG techniques like Query transformation and Routing, both involving LLMs and thus representing agentic behaviour — some complex logic involving LLM reasoning within our RAG pipeline.
現在該進入更精巧的 RAG 技術了,如查詢轉換 (Query transformation) 與路由 (Routing),兩者都涉及 LLM,因此代表了代理 (agentic) 行為——在我們的 RAG 管線中涉及 LLM 推理的某些複雜邏輯。
4. Query transformations / 4. 查詢轉換¶
Query transformations are a family of techniques using an LLM as a reasoning engine to modify user input in order to improve retrieval quality. There are different options to do that.
查詢轉換是一系列技術,使用 LLM 作為推理引擎來修改使用者的輸入,以提升檢索品質。 有不同的方式可以做到這點。
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
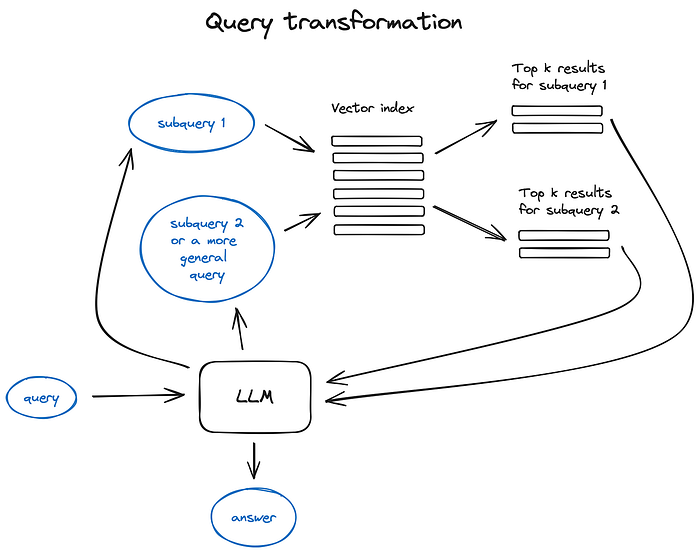
Query transformation principles illustrated
查詢轉換原理圖解
If the query is complex, LLM can decompose it into several sub queries. For examle, if you ask:
— “What framework has more stars on Github, Langchain or LlamaIndex?”,and it is unlikely that we’ll find a direct comparison in some text in our corpus so it makes sense to decompose this question in two sub-queries presupposing simpler and more concrete information retrieval:
— “How many stars does Langchain have on Github?”
— “How many stars does Llamaindex have on Github?”They would be executed in parallel and then the retrieved context would be combined in a single prompt for LLM to synthesize a final answer to the initial query. Both libraries have this functional implemented — as a Multi Query Retriever in Langchain and as a Sub Question Query Engine in Llamaindex.
如果查詢很複雜,LLM 可以將它分解成數個子查詢 (sub query)。 例如,如果你問:
—「Langchain 和 LlamaIndex,哪個框架在 Github 上有更多星星?」,而我們不太可能在語料庫的某段文字中找到直接的比較,因此將這個問題分解成兩個預設更簡單、更具體資訊檢索的子查詢是合理的:
—「Langchain 在 Github 上有多少星星?」
—「Llamaindex 在 Github 上有多少星星?」 它們會被平行執行,然後檢索到的脈絡會被結合進單一提示詞中,供 LLM 綜合出對初始查詢的最終答案。兩個函式庫都實作了這項功能——在 Langchain 中為 Multi Query Retriever,在 Llamaindex 中為 Sub Question Query Engine。
-
Step-back prompting uses LLM to generate a more general query, retrieving for which we obtain a more general or high-level context useful to ground the answer to our original query on.
Retrieval for the original query is also performed and both contexts are fed to the LLM on the final answer generation step.
Here is a LangChain implementation. -
退一步提示法 (Step-back prompting) 使用 LLM 來生成一個更概括的查詢,針對它進行檢索可獲得一個更概括或更高層次的脈絡,有助於為我們原始查詢的答案提供依據。
原始查詢的檢索也會執行,並在最終答案生成步驟中將兩個脈絡都輸入給 LLM。
這裡有一個 LangChain 的實作。 -
Query re-writing uses LLM to reformulate initial query in order to improve retrieval. Both LangChain and LlamaIndex have implementations, tough a bit different, I find LlamaIndex solution being more powerful here.
-
查詢重寫 (Query re-writing) 使用 LLM 來重新表述初始查詢,以改善檢索。LangChain 與 LlamaIndex 都有實作,雖然略有不同,但我認為 LlamaIndex 的方案在這方面更為強大。
Reference citations / 來源引用¶
This one goes without a number as this is more an instrument than a retrieval improvement technique, although a very important one.
If we’ve used multiple sources to generate an answer either due to the initial query complexity (we had to execute multiple subqueries and then to combine retrieved context in one answer), or because we found relevant context for a single query in various documents, the question rises if we could accurately back reference our sources.
這一項沒有編號,因為它更像是一個工具,而非檢索改善技術,儘管它非常重要。
如果我們使用了多個來源來生成答案,無論是由於初始查詢的複雜性(我們必須執行多個子查詢,然後將檢索到的脈絡結合成一個答案),還是因為我們在不同文件中為單一查詢找到了相關脈絡,問題便浮現:我們能否準確地回溯引用我們的來源。
There are a couple of ways to do that:
有幾種做法:
-
Insert this referencing task into our prompt and ask LLM to mention ids of the used sources.
-
將這項引用任務插入我們的提示詞中,並要求 LLM 提及所使用來源的 id。
-
Match the parts of generated response to the original text chunks in our index — llamaindex offers an efficient fuzzy matching based solution for this case. In case you have not heard of fuzzy matching, this is an incredibly powerful string matching technique.
-
將生成回應的各部分與我們索引中的原始文字區塊進行匹配——llamaindex 為此情況提供了一個高效的基於模糊匹配 (fuzzy matching) 的解決方案。如果你沒聽過模糊匹配,這是一種極其強大的字串匹配技術。
5. Chat Engine / 5. 對話引擎 (Chat Engine)¶
The next big thing about building a nice RAG system that can work more than once for a single query is the chat logic, taking into account the dialogue context, same as in the classic chat bots in the pre-LLM era.
This is needed to support follow up questions, anaphora, or arbitrary user commands relating to the previous dialogue context. It is solved by query compression technique, taking chat context into account along with the user query.
要建立一個能在單一查詢之外多次運作的優良 RAG 系統,下一件大事是考量對話脈絡的對話邏輯,這與 LLM 出現之前時代的經典聊天機器人 (chat bot) 相同。
這對於支援追問、指代 (anaphora),或與先前對話脈絡相關的任意使用者指令而言是必需的。它透過將對話脈絡與使用者查詢一併納入考量的查詢壓縮技術來解決。
As always, there are several approaches to said context compression —
a popular and relatively simple ContextChatEngine, first retrieving context relevant to user’s query and then sending it to LLM along with chat history from the memory buffer for LLM to be aware of the previous context while generating the next answer.
一如既往,對於上述脈絡壓縮有幾種方法——
一個受歡迎且相對簡單的 ContextChatEngine,首先檢索與使用者查詢相關的脈絡,然後將其連同來自記憶 (memory) 緩衝區的對話歷史一起送給 LLM,讓 LLM 在生成下一個答案時能知曉先前的脈絡。
A bit more sophisticated case is CondensePlusContextMode — there in each interaction the chat history and last message are condensed into a new query, then this query goes to the index and the retrieved context is passed to the LLM along with the original user message to generate an answer.
一個稍微精巧一點的案例是 CondensePlusContextMode——其中在每次互動時,對話歷史與最後一則訊息會被濃縮 (condense) 成一個新查詢,然後這個查詢送進索引,檢索到的脈絡再連同原始使用者訊息一起傳給 LLM 以生成答案。
It’s important to note that there is also support for OpenAI agents based Chat Engine in LlamaIndex providing a more flexible chat mode and Langchain also supports OpenAI functional API.
值得注意的是,LlamaIndex 中也支援基於 OpenAI 代理的對話引擎,提供更靈活的對話模式,而 Langchain 也支援 OpenAI 的函式 API。
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
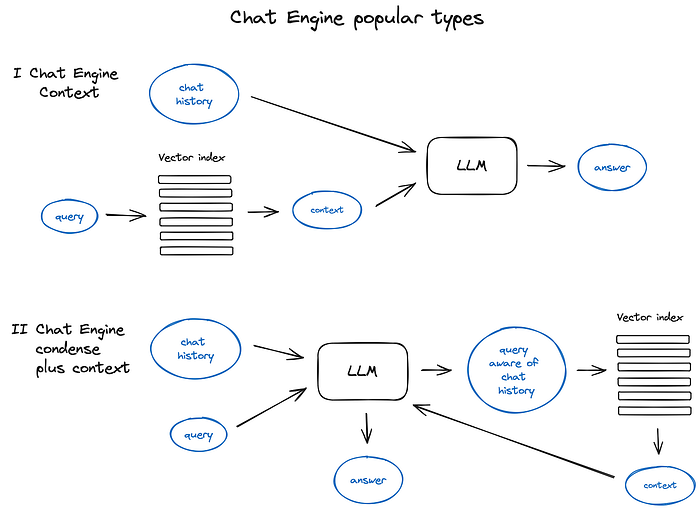
An illustration of different Chat Engine types and principles
不同對話引擎類型與原理的圖解
There are other Chat engine types like ReAct Agent, but let’s skip to Agents themselves in section 7.
還有其他對話引擎類型,如 ReAct Agent,但讓我們直接跳到第 7 節的代理本身。
6. Query Routing / 6. 查詢路由¶
Query routing is the step of LLM-powered decision making upon what to do next given the user query — the options usually are to summarise, to perform search against some data index or to try a number of different routes and then to synthesise their output in a single answer.
查詢路由是在給定使用者查詢的情況下,由 LLM 驅動決定下一步該做什麼的步驟——選項通常是進行摘要、針對某個資料索引執行搜尋,或嘗試多種不同的路徑然後將它們的輸出綜合成一個答案。
Query routers are also used to select an index, or, broader, data store, where to send user query — either you have multiple sources of data, for example, a classic vector store and a graph database or a relational DB, or you have an hierarchy of indices — for a multi-document storage a pretty classic case would be an index of summaries and another index of document chunks vectors for example.
查詢路由器也用於選擇要將使用者查詢送往哪個索引,或更廣義地說,哪個資料儲存區 (data store)——可能是你有多個資料來源,例如一個經典的向量儲存區與一個圖資料庫 (graph database) 或一個關聯式資料庫 (relational DB),也可能是你有一個索引的階層——以多文件儲存為例,一個相當經典的情況會是一個摘要索引與另一個文件區塊向量索引。
Defining the query router includes setting up the choices it can make.
The selection of a routing option is performed with an LLM call, returning its result in a predefined format, used to route the query to the given index, or, if we are taking of the agnatic behaviour, to sub-chains or even other agents as shown in the Multi documents agent scheme below.
定義查詢路由器包括設定它所能做的選擇。
路由選項的選擇透過一次 LLM 呼叫來執行,以預先定義的格式回傳其結果,用於將查詢路由到給定的索引,或者,如果我們談的是代理行為,則路由到子鏈 (sub-chain) 甚至其他代理,如下方的多文件代理方案所示。
Both LlamaIndex and LangChain have support for query routers.
LlamaIndex 與 LangChain 都支援查詢路由器。
7. Agents in RAG / 7. RAG 中的代理¶
Agents (supported both by Langchain and LlamaIndex) have been around almost since the first LLM API has been released — the idea was to provide an LLM, capable of reasoning, with a set of tools and a task to be completed. The tools might include some deterministic functions like any code function or an external API or even other agents — this LLM chaining idea is where LangChain got its name from.
代理(Langchain 與 LlamaIndex 都支援)幾乎從第一個 LLM API 發布以來就已存在——其構想是為一個能夠推理的 LLM 提供一組工具和一項待完成的任務。這些工具可能包括某些確定性 (deterministic) 函式,如任何程式碼函式、外部 API,甚至其他代理——這種 LLM 鏈接 (chaining) 的構想正是 LangChain 名稱的由來。
Agents are a huge thing itself and it’s impossible to make a deep enough dive into the topic inside a RAG overview, so I’ll just continue with the agent-based multi document retrieval case, making a short stop at the OpenAI Assistants stationas it’s a relatively new thing, presented at the recent OpenAI dev conference as GPTs, and working under the hood of the RAG system described below.
代理本身就是一個龐大的主題,在 RAG 總覽中不可能對其做足夠深入的探討,因此我只會繼續介紹基於代理的多文件檢索案例,並在 OpenAI Assistants 這一站稍作停留,因為它是個相對較新的東西,在近期的 OpenAI 開發者大會上以 GPTs 形式發表,並在下文所述 RAG 系統的底層運作。
OpenAI Assistants basically have implemented a lot of tools needed around an LLM that we previously had in open source — a chat history, a knowledge storage, a document uploading interface and, maybe most important, function calling API. This latter provides capabilities to convert natural language into API calls to external tools or database queries.
OpenAI Assistants 基本上實作了許多我們先前在開源中才有的、圍繞 LLM 所需的工具——對話歷史、知識儲存、文件上傳介面,以及或許最重要的函式呼叫 API (function calling API)。後者提供了將自然語言轉換成對外部工具的 API 呼叫或資料庫查詢的能力。
In LlamaIndex there is an OpenAIAgent class marrying this advanced logic with the ChatEngine and QueryEngine classes, providing knowledge-based and context aware chatting along with the ability of multiple OpenAI functions calls in one conversation turn, which really brings the smart agentic behaviour.
在 LlamaIndex 中有一個 OpenAIAgent 類別,將這套進階邏輯與 ChatEngine 及 QueryEngine 類別結合起來,提供基於知識且具脈絡感知的對話,並具備在單一對話回合中多次呼叫 OpenAI 函式的能力,這真正帶來了聰明的代理行為。
Let’s take a look at the Multi-Document Agents scheme — a pretty sophisticated setting, involving initialisation of an agent (OpenAIAgent) upon each document, capable of doc summarisation and the classic QA mechanics, and a top agent, responsible for queries routing to doc agents and for the final answer synthesis.
讓我們來看看多文件代理 (Multi-Document Agents) 方案——一個相當精巧的設定,涉及為每份文件初始化一個代理(OpenAIAgent),它能進行文件摘要與經典的問答機制,以及一個頂層代理 (top agent),負責將查詢路由給各文件代理並負責最終答案的綜合。
Each document agent has two tools — a vector store index and a summary index, and based on the routed query it decides which one to use.
And for the top agent, all document agents are tools respectfully.
每個文件代理有兩個工具——一個向量儲存索引與一個摘要索引,並根據被路由過來的查詢決定使用哪一個。
而對頂層代理而言,所有文件代理分別都是工具。
This scheme illustrates an advanced RAG architecture with a lot of routing decisions made by each involved agent. The benefit of such approach is the ability to compare different solutions or entities, described in different documents and their summaries along with the classic single doc summarisation and QA mechanics — this basically covers the most frequent chat-with-collection-of-docs usecases.
這個方案展示了一個進階 RAG 架構,其中每個涉及的代理都做出大量的路由決策。這種方法的好處在於能夠比較描述於不同文件及其摘要中的不同解決方案或實體,同時兼具經典的單文件摘要與問答機制——這基本上涵蓋了最常見的「與文件集合對話」使用案例。
Press enter or click to view image in full size
按 Enter 或點擊以檢視完整尺寸圖片
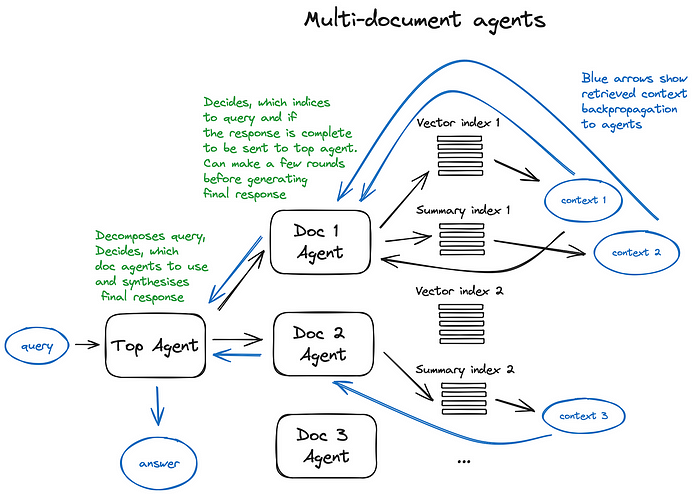
A scheme illustrating multi document agents, involving both query routing and agentic behavior patterns.
一張展示多文件代理的示意圖,同時涉及查詢路由與代理行為模式。
The drawback of such a complex scheme can be guessed from the picture — it’s a bit slow due to multiple back and forth iterations with the LLMs inside our agents. Just in case, an LLM call is always the longest operation in a RAG pipeline — search is optimised for speed by design. So for a large multi document storage I’d recommed to think of some simplifications to this scheme making it scalable.
這種複雜方案的缺點從圖中即可猜到——由於在我們的代理內部與 LLM 之間多次來回迭代,它有點慢。順帶一提,LLM 呼叫始終是 RAG 管線中耗時最長的操作——搜尋在設計上就是為速度而最佳化的。因此對於大型多文件儲存,我會建議思考對這個方案做一些簡化,使其具備可擴展性。
8. Response synthesiser / 8. 回應合成器¶
This is the final step of any RAG pipeline — generate an answer based on all the context we carefully retrieved and on the initial user query.
The simplest approach would be just to concatenate and feed all the fetched context (above some relevance threshold) along with the query to an LLM at once.
But, as always, there are other more sophisticated options involving multiple LLM calls to refine retrieved context and generate a better answer.
這是任何 RAG 管線的最後一步——根據我們精心檢索的所有脈絡與初始使用者查詢來生成一個答案。
最簡單的方法就是把所有取得的脈絡(高於某個相關性閾值)連同查詢一次串接 (concatenate) 起來輸入給 LLM。
但一如既往,還有其他更精巧的選項,涉及多次 LLM 呼叫來精煉檢索到的脈絡並生成更好的答案。
The main approaches to response synthesis are:1. iteratively refine the answer by sending retrieved context to LLM chunk by chunk 2. summarise the retrieved context to fit into the prompt3. generate multiple answers based on different context chunks and then to concatenate or summarise them.
For more details please check the Response synthesizer module docs.
回應合成的主要方法有: 1. 透過逐區塊地將檢索到的脈絡送給 LLM 來反覆精煉答案;2. 將檢索到的脈絡摘要化以符合提示詞長度;3. 根據不同的脈絡區塊生成多個答案,然後將它們串接或摘要化。
更多細節請查看回應合成器模組文件。
Encoder and LLM fine-tuning / 編碼器與 LLM 微調¶
This approach involves fine-tuning of some of the two DL models involved in our RAG pipeline — either the Transformer Encoder, resposible for embeddings quality and thus context retrieval quality or an LLM, responsible for the best usage of the provided context to answer user query — luckily, the latter is a good few shot learner.
這種方法涉及對我們 RAG 管線中所牽涉的兩個深度學習 (DL) 模型進行微調 (fine-tuning)——可以是 Transformer 編碼器,它負責嵌入品質,進而負責脈絡檢索品質,也可以是 LLM,它負責最佳地運用所提供的脈絡來回答使用者查詢——所幸,後者是個優秀的少樣本學習者 (few shot learner)。
One big advantage nowadays is the availability of high-end LLMs like GPT-4 to generate high quality synthetic datasets.
But you should always be aware that taking an open-source model trained by professional research teams on carefully collected, cleaned and validated large datasets and making a quick tuning using small synthetic dataset might narrow down the model’s capabilities in general.
如今的一大優勢是可以取得像 GPT-4 這樣的高階 LLM 來生成高品質的合成資料集 (synthetic dataset)。
但你應該始終留意,拿一個由專業研究團隊在精心蒐集、清理並驗證過的大型資料集上訓練出來的開源模型,再用小型合成資料集做快速微調,可能會整體上縮窄模型的能力。
Encoder fine-tuning / 編碼器微調¶
I’ve also been a bit skeptical about the Encoder funetuning approach as the latest Transformer Encoders optimised for search are pretty efficient.
So I have tested the performance increase provided by finetuning of bge-large-en-v1.5 (top 4 of the MTEB leaderboard at the time of writing) in the LlamaIndex notebook setting, and it demonstrated a 2% retrieval quality increase. Nothing dramatic but it is nice to be aware of that option, especially if you have a narrow domain dataset you’re building RAG for.
我對編碼器微調的方法也曾有點懷疑,因為最新的、針對搜尋最佳化的 Transformer 編碼器已經相當高效。
因此我在 LlamaIndex notebook 的設定中測試了微調 bge-large-en-v1.5(撰寫本文時為 MTEB 排行榜前四名)所帶來的效能提升,結果顯示檢索品質提升了 2%。雖然不算驚人,但能知曉這個選項是好事,尤其是如果你正在為一個狹窄領域的資料集建構 RAG。
Ranker fine-tuning / 排序器微調¶
The other good old option is to have a cross-encoder for reranking your retrieved results if you dont trust your base Encoder completely.
It works the following way — you pass the query and each of the top k retrieved text chunks to the cross-encoder, separated by a SEP token, and fine-tune it to output 1 for relevant chunks and 0 for non-relevant.
A good example of such tuning process could be found here, the results say the pairwise score was improved by 4% by cross-encoder finetuning.
另一個歷久彌新的選項是,如果你不完全信任你的基礎編碼器,可以用一個交叉編碼器來對你檢索到的結果重新排序。
它的運作方式如下——你將查詢與前 k 個檢索到的文字區塊各自以一個 SEP 詞元分隔後傳給交叉編碼器,並微調它對相關區塊輸出 1、對不相關區塊輸出 0。
這種微調流程的一個好例子可在此處找到,結果顯示交叉編碼器微調使成對分數 (pairwise score) 提升了 4%。
LLM fine-tuning / LLM 微調¶
Recently OpenAI started providing LLM finetuning API and LlamaIndex has a tutorial on finetuning GPT-3.5-turbo in RAG setting to “distill” some of the GPT-4 knowledge. The idea here is to take a document, generate a number of questions with GPT-3.5-turbo, then use GPT-4 to generate answers to these questions based on the document contents (build a GPT4-powered RAG pipeline) and then to fine-tune GPT-3.5-turbo on that dataset of question-answer pairs. The ragas framework used for the RAG pipeline evaluation shows a 5% increase in the faithfulness metrics, meaning the fine-tuned GPT 3.5-turbo model made a better use of the provided context to generate its answer, than the original one.
近期 OpenAI 開始提供 LLM 微調 API,而 LlamaIndex 有一份關於在 RAG 設定中微調 GPT-3.5-turbo 以「蒸餾 (distill)」部分 GPT-4 知識的教學。這裡的構想是:拿一份文件,用 GPT-3.5-turbo 生成若干問題,然後用 GPT-4 根據文件內容生成這些問題的答案(建立一個由 GPT4 驅動的 RAG 管線),接著在這個問答對的資料集上微調 GPT-3.5-turbo。用於評估 RAG 管線的 ragas 框架顯示忠實度 (faithfulness) 指標提升了 5%,意味著微調後的 GPT 3.5-turbo 模型比原始模型更好地運用了所提供的脈絡來生成其答案。
A bit more sophisticated approach is demonstrated in the recent paper RA-DIT: Retrieval Augmented Dual Instruction Tuning by Meta AI Research, suggesting a technique to tune both the LLM and the Retriever
(a Dual Encoder in the original paper) on triplets of query, context and answer. For the implementations details please refer to this guide.
This technique was used both to fine-tune OpenAI LLMs through the fine-tuning API and Llama2 open-source model (in the original paper), resulting in ~5% increase in knowledge-intense tasks metrics (compared to Llama2 65B with RAG) and a couple percent increase in common sense reasoning tasks.
Meta AI Research 近期的論文 RA-DIT: Retrieval Augmented Dual Instruction Tuning(檢索增強的雙重指令微調) 展示了一個稍微更精巧的方法,提出一種在「查詢、脈絡、答案」三元組 (triplet) 上同時微調 LLM 與檢索器 (Retriever)(原論文中為雙重編碼器 Dual Encoder)的技術。實作細節請參閱這份指南。
這項技術既被用於透過微調 API 微調 OpenAI 的 LLM,也被用於微調 Llama2 開源模型(在原論文中),結果在知識密集型任務指標上提升了約 5%(相較於搭配 RAG 的 Llama2 65B),並在常識推理任務上提升了數個百分點。
In case you know better approaches to LLM finetuning for RAG, please share your expertise in the comments section, especially if they are applied to the smaller open source LLMs.
如果你知道有更好的、針對 RAG 的 LLM 微調方法,請在留言區分享你的專業見解,尤其是若它們應用於較小的開源 LLM。
Evaluation / 評估¶
There are several frameworks for RAG systems performance evaluation sharing the idea of having a few separate metrics like overall answer relevance, answer groundedness, faithfulness and retrieved context relevance.
有數個用於 RAG 系統效能評估的框架,它們共享一個構想:設立幾項各自獨立的指標,如整體的答案相關性 (answer relevance)、答案依據性 (groundedness)、忠實度 (faithfulness) 以及檢索脈絡相關性 (retrieved context relevance)。
Ragas, mentioned in the previous section, uses faithfulness and answer relevance as the generated answer quality metrics and classic context precision and recall for the retrieval part of the RAG scheme.
前一節提到的 Ragas 使用忠實度與答案相關性作為生成答案的品質指標,並使用經典的脈絡精確率 (precision) 與召回率 (recall) 來評估 RAG 方案中的檢索部分。
In a recently released great short course Building and Evaluating Advanced RAG by Andrew NG, LlamaIndex and the evaluation framework Truelens, they suggest the RAG triad — retrieved context relevance to the query, groundedness (how much the LLM answer is supported by the provided context) and answer relevance to the query.
在一門近期推出、由吳恩達 (Andrew NG)、LlamaIndex 與評估框架 Truelens 合作的優秀短期課程《建構與評估進階 RAG》中,他們提出了 RAG 三要素 (RAG triad)——檢索脈絡對查詢的相關性、依據性(LLM 答案被所提供脈絡支持的程度),以及答案對查詢的相關性。
The key and the most controllable metric is the retrieved context relevance — basically parts 1–7 of the advanced RAG pipeline described above plus the Encoder and Ranker fine-tuning sections are meant to improve this metric, while part 8 and LLM fine-tuning are focusing on answer relevance and groundedness.
關鍵且最可掌控的指標是檢索脈絡相關性——基本上,上文所述進階 RAG 管線的第 1 至 7 部分加上編碼器與排序器的微調章節都旨在改善這項指標,而第 8 部分與 LLM 微調則著重於答案相關性與依據性。
A good example of a pretty simple retriever evaluation pipeline could be found here and it was applied in the Encoder fine-tuning section.
A bit more advanced approach taking into account not only the hit rate, but the Mean Reciprocal Rank, a common search engine metric, and also generated answer metrics such as faithfulness abd relevance, is demonstrated in the OpenAI cookbook.
一個相當簡單的檢索器評估管線的好例子可在此處找到,它被應用在編碼器微調章節中。
一個稍微更進階的方法,不僅考量命中率 (hit rate),還考量常見的搜尋引擎指標平均倒數排名 (Mean Reciprocal Rank),以及生成答案的指標如忠實度與相關性,則在 OpenAI cookbook 中有所展示。
LangChain has a pretty advanced evaluation framework LangSmith where custom evaluators may be implemented plus it monitors the traces running inside your RAG pipeline in order to make your system more transparent.
LangChain 有一個相當進階的評估框架 LangSmith,可在其中實作自訂的評估器,此外它還會監控在你 RAG 管線內部執行的軌跡 (trace),以使你的系統更為透明。
In case you are building with LlamaIndex, there is a rag_evaluator llama pack, providing a quick tool to evaluate your pipeline with a public dataset.
如果你正用 LlamaIndex 進行建構,有一個 rag_evaluator llama pack,提供一個快速工具,讓你能用公開資料集評估你的管線。
Conclusion / 結論¶
I tried to outline the core algorithmic approaches to RAG and to illustrate some of them in hopes this might spark some novel ideas to try in your RAG pipeline, or bring some system to the vast variety of tecniques that have been invented this year — for me 2023 was the most exciting year in ML so far.
我試著勾勒出 RAG 的核心演算法方法,並圖解了其中一些,希望這能激發一些新穎的想法供你在 RAG 管線中嘗試,或為今年所發明的繁多技術帶來一些系統性的梳理——對我而言,2023 年是迄今機器學習領域最令人興奮的一年。
There are many more other things to consider like web search based RAG (RAGs by LlamaIndex, webLangChain, etc), taking a deeper dive into agentic architectures (and the recent OpenAI stake in this game) and some ideas on LLMs Long-term memory.
還有許多其他事情值得考量,如基於網路搜尋的 RAG(LlamaIndex 的 RAGs、webLangChain 等)、更深入地探討代理架構(以及近期 OpenAI 在這場賽局中的押注),以及一些關於 LLM 長期記憶 (Long-term memory) 的想法。
The main production challenge for RAG systems besides answer relevance and faithfulness is speed, especially if you are into the more flexible agent-based schemes, but that’s a thing for another post. This streaming feature ChatGPT and most other assistants use is not a random cyberpunk style, but merely a way to shorten the perceived answer generation time.
That is why I see a very bright future for the smaller LLMs and recent releases of Mixtral and Phi-2 are leading us in this direction.
除了答案相關性與忠實度之外,RAG 系統在生產環境中的主要挑戰是速度,尤其是如果你投入更靈活的、基於代理的方案,但那是另一篇文章的主題了。ChatGPT 與多數其他助理所使用的這種串流 (streaming) 功能並非隨意的賽博龐克 (cyberpunk) 風格,而僅僅是一種縮短答案生成感知時間的方法。
這就是為什麼我看好較小型 LLM 的光明未來,而近期 Mixtral 與 Phi-2 的發布正引領我們朝這個方向前進。
Thank you very much for reading this long post!
非常感謝你閱讀這篇長文!
The main references are collected in my knowledge base, there is a co-pilot to chat with this set of documents: https://app.iki.ai/playlist/236.
主要的參考資料都蒐集在我的知識庫中,那裡有一個副駕駛 (co-pilot) 可供你與這組文件對話: https://app.iki.ai/playlist/236。