Does GraphRAG Really Outperform RAG? / GraphRAG 真的勝過 RAG 嗎?¶
Author: Florian June 作者:Florian June
Published: 發布日期:
Source: https://pub.towardsai.net/does-graphrag-really-outperform-rag-6c1a32c50683 來源:https://pub.towardsai.net/does-graphrag-really-outperform-rag-6c1a32c50683
Fetched: 2026-06-07T02:50:28.207776 擷取時間:2026-06-07T02:50:28.207776
Does GraphRAG Really Outperform RAG? / GraphRAG 真的勝過 RAG 嗎?¶
If you've ever asked yourself, "Does GraphRAG really outperform vanilla RAG — and by how much?", you're not alone. It's a question that's been floating around among devs and researchers alike, especially those working on RAG tasks.
如果你曾經問過自己:「GraphRAG 真的勝過原始的 RAG (Retrieval-Augmented Generation,檢索增強生成) 嗎?又勝過多少?」,那你並不孤單。這是一個在開發者與研究人員之間流傳已久的問題,尤其是那些正在處理 RAG 任務的人。
A recent study dives right into this exact question, using a focused and rigorous setup: textbook-level retrieval QA, page by page.
最近的一項研究正好深入探討了這個問題,採用了一個聚焦且嚴謹的設定:教科書層級的檢索式問答 (Retrieval QA),逐頁進行。
It used the undergraduate math textbook "An Infinite Descent into Pure Mathematics" as their dataset. After OCR processing using the GPT Vision model, they created a custom benchmark of 477 samples, which were manually reviewed and filtered down from an initial set of 628. Each consisting of a question, answer, and the specific textbook page it's based on.
這項研究使用了大學數學教科書《An Infinite Descent into Pure Mathematics》作為他們的資料集。在使用 GPT Vision 模型進行光學字元辨識 (OCR, Optical Character Recognition) 處理後,他們建立了一個包含 477 個樣本的自訂基準 (benchmark),這些樣本是從最初的 628 個樣本中經人工審查並篩選而來。每個樣本都包含一個問題、一個答案,以及其所依據的特定教科書頁面。
RAG Settings / RAG 設定¶
For the baseline RAG, It tested five popular embedding models (think: voyage-3-large, nvidia/nv-embed-v2, and others). On the other hand, GraphRAG was built to leverage inter-page relationships—essentially modeling how concepts flow across pages to support richer retrieval context.
對於基準 RAG,研究測試了五個熱門的嵌入模型 (embedding model)(例如:voyage-3-large、nvidia/nv-embed-v2 等)。另一方面,GraphRAG 的建構則是為了善用頁面間的關係 (inter-page relationships)——本質上是對概念如何跨頁面流動進行建模,以支援更豐富的檢索脈絡。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視全尺寸圖片
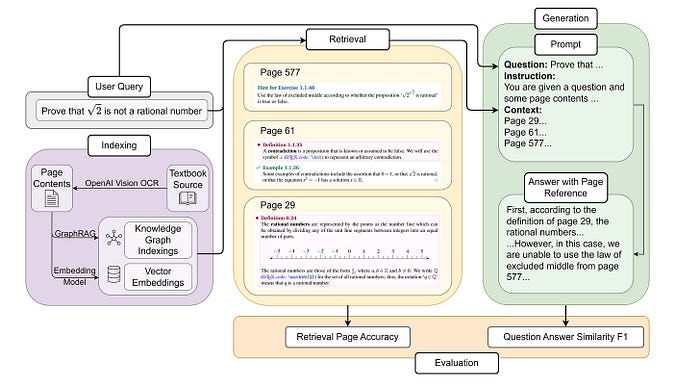
Figure 1: A representative diagram of RAG pipeline. [Source].
圖 1:RAG 流程 (pipeline) 的代表性示意圖。[來源]。
Figure 1 is a quick breakdown of how the RAG pipeline works, illustrated through a simple three-step process:
圖 1 透過一個簡單的三步驟流程,快速拆解了 RAG 流程的運作方式:
-
Indexing. First, the source documents are either embedded into vectors or structured as relational entities when using GraphRAG. This step sets the foundation for everything that follows.
-
索引 (Indexing)。首先,來源文件會被嵌入為向量,或者在使用 GraphRAG 時被結構化為關係實體 (relational entities)。這個步驟為後續的一切奠定了基礎。
-
Retrieval. Given a user query, the system searches for the top-k most relevant pages or entities based on semantic similarity. The goal is to pull in the most useful context to help answer the question.
-
檢索 (Retrieval)。給定一個使用者查詢,系統會根據語意相似度 (semantic similarity) 搜尋出排名前 k 個最相關的頁面或實體。目標是擷取最有用的脈絡來協助回答問題。
-
Generation. Finally, the model takes in the query, the prompt, and the retrieved content, then generates an answer using a large language model.
-
生成 (Generation)。最後,模型接收查詢、提示詞 (prompt) 與檢索到的內容,然後使用大型語言模型 (LLM, Large Language Model) 生成答案。
GraphRAG Settings / GraphRAG 設定¶
The baseline setup follows the GraphRAG pipeline from Microsoft Research. It starts with entity and relation extraction from textbook pages, then builds a knowledge graph, and finally performs graph-based retrieval and generation. Each node in the graph carries its source snippet to keep things traceable.
基準設定遵循微軟研究院 (Microsoft Research) 的 GraphRAG 流程。它首先從教科書頁面中進行實體與關係的抽取 (entity and relation extraction),接著建立知識圖譜 (Knowledge Graph),最後執行基於圖譜的檢索與生成。圖譜中的每個節點 (node) 都帶有其來源片段 (snippet),以保持可追溯性。
But this study didn't stop there. They introduced some key improvements to make the pipeline more transparent and page-aware. Specifically, they explicitly tagged each knowledge entity and text chunk with document_ids and entity_ids, and added parameters like include_document_ids to the context-building functions. This allows every retrieved item to be linked back to its exact page number in the textbook.
但這項研究並未止步於此。他們引入了一些關鍵改進,使流程更加透明且具備頁面感知能力 (page-aware)。具體來說,他們明確地為每個知識實體與文字區塊 (text chunk) 標記 document_ids 與 entity_ids,並在脈絡建構函式 (context-building functions) 中加入了像是 include_document_ids 的參數。這使得每個被檢索到的項目都能連結回它在教科書中確切的頁碼。
Evaluation / 評估¶
To evaluate performance, there are two main metrics.
為了評估效能,主要有兩個指標 (metrics)。
The first is Retrieval Page Accuracy, which measures how often the correct page is successfully retrieved. The second is Question Answer Similarity F1, which looks at the overlap between the model's output and the ground-truth answer. This is calculated using shared words. Precision captures how much of the output overlaps with the ground truth, while recall measures how much of the ground truth is covered in the output. The F1 score balances both, giving a sense of overall alignment.
第一個是檢索頁面準確度 (Retrieval Page Accuracy),用來衡量正確頁面被成功檢索的頻率。第二個是問答相似度 F1 (Question Answer Similarity F1),它檢視模型輸出與標準答案 (ground-truth answer) 之間的重疊程度。這是透過共享詞彙來計算的。精確率 (Precision) 捕捉輸出中有多少與標準答案重疊,而召回率 (Recall) 則衡量標準答案中有多少被輸出涵蓋。F1 分數在兩者之間取得平衡,提供了一種整體一致性的衡量感受。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視全尺寸圖片
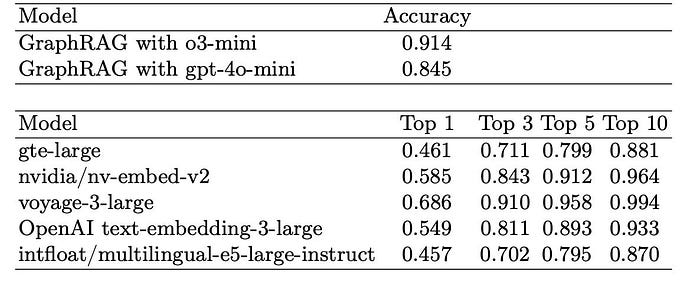
Figure 2: Target Page Retrieval Accuracy for different models. [Source].
圖 2:不同模型的目標頁面檢索準確度。[來源]。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視全尺寸圖片
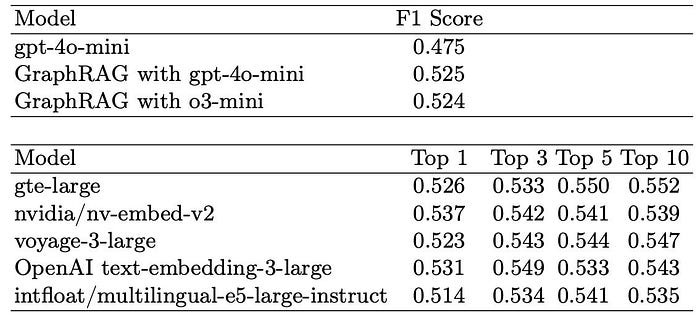
Figure 3: F1 Score for Answer Generation Performance for different models. [Source].
圖 3:不同模型在答案生成效能上的 F1 分數。[來源]。
So, how does GraphRAG actually perform?
那麼,GraphRAG 的實際表現如何呢?
The results are mixed. In terms of Retrieval Accuracy, it performs very well (achieving 0.914 with o3-mini), comparable to the Top-3 performance of the best RAG models. However, regarding the F1 score for generated answers, it does underperform compared to most RAG setups.
結果是好壞參半的。在檢索準確度方面,它表現得非常好(使用 o3-mini 達到 0.914),可與最佳 RAG 模型的 Top-3 表現相媲美。然而,在生成答案的 F1 分數方面,它的表現確實不如大多數的 RAG 設定。
One key issue is redundancy. Because GraphRAG retrieves related entities rather than just the most relevant page, it often pulls in extra content that isn't directly helpful. This extra noise tends to dilute the quality of the generated answers.
一個關鍵問題是冗餘性 (redundancy)。因為 GraphRAG 檢索的是相關實體,而不只是最相關的頁面,所以它常常會帶入並非直接有用的額外內容。這些額外的雜訊往往會稀釋生成答案的品質。
In terms of F1 score, GraphRAG falls behind most of the embedding-based RAG models. The extra context doesn't always align well with the structure of textbook pages, which makes it harder for the model to stay on target.
在 F1 分數方面,GraphRAG 落後於大多數基於嵌入的 RAG 模型。額外的脈絡並不總是能與教科書頁面的結構良好對齊,這使得模型更難切中目標。
The takeaway is pretty clear. For page-level question answering on math textbooks, traditional embedding-based RAG is currently the better choice. GraphRAG still struggles with quality of answer generation and page alignment, which limits its overall effectiveness.
結論相當明確。對於數學教科書上的頁面層級問答,傳統的基於嵌入的 RAG 目前是更好的選擇。GraphRAG 在答案生成品質與頁面對齊 (page alignment) 方面仍然有所掙扎,這限制了它整體的效用。
Thoughts / 一些想法¶
I want to share a few thoughts.
我想分享幾點想法。
The granularity in this task is page-to-page — you ask a question about one page and expect an answer grounded on that same page. But GraphRAG's graph connects concept-to-concept. That gap matters. A better approach might be to construct a graph of pages, where each node represents a page and edges represent section structure, formula dependencies, or cross-page references. Then, only expand the neighborhood when confidence is low, to reduce noise and manage costs.
這項任務的粒度 (granularity) 是頁對頁的——你針對某一頁提出問題,並期望得到一個立基於同一頁的答案。但 GraphRAG 的圖譜連結的是概念對概念。這個落差很重要。一個更好的做法或許是建構一個頁面圖譜 (graph of pages),其中每個節點代表一個頁面,而邊 (edges) 則代表章節結構、公式依賴關係或跨頁參照。接著,僅在信賴度 (confidence) 較低時才擴展鄰域 (neighborhood),以減少雜訊並控制成本。
In addition, evaluation should go beyond just page hits and F1 scores. In a real textbook setting, what matters more is instructional sufficiency and reference robustness — things like whether nearby pages are meaningfully linked, whether key definitions and formulas are covered, and whether references hold up consistently. These are the metrics that better reflect the true value of retrieval in an educational context.
此外,評估不應只侷限於頁面命中率與 F1 分數。在真實的教科書情境中,更重要的是教學充分性 (instructional sufficiency) 與參照穩健性 (reference robustness)——像是鄰近頁面是否有意義地連結、關鍵定義與公式是否被涵蓋,以及參照是否能一致地成立。這些才是能更好地反映檢索在教育情境中真正價值的指標。
My Latest Articles: aiexpjourney.substack.com.
我的最新文章: aiexpjourney.substack.com。