Why LLMs Fail at Knowledge Graph Extraction (And What Works Instead) / 為什麼大型語言模型在知識圖譜抽取上會失敗(以及什麼方法才有效)¶
Author: Fabio Yáñez Romero 作者:Fabio Yáñez Romero
Published: 發表日期:
Source: https://pub.towardsai.net/why-llms-fail-at-knowledge-graph-extraction-and-what-works-instead-dcb029f35f5b 來源:https://pub.towardsai.net/why-llms-fail-at-knowledge-graph-extraction-and-what-works-instead-dcb029f35f5b
Fetched: 2026-06-07T02:52:34.141615 擷取時間:2026-06-07T02:52:34.141615
Why LLMs Fail at Knowledge Graph Extraction (And What Works Instead) / 為什麼大型語言模型在知識圖譜抽取上會失敗(以及什麼方法才有效)¶
From Entity Extraction to Graph Augmentation: What Every ML Engineer Needs to Know / 從實體抽取到圖譜增強:每位機器學習工程師都該知道的事¶
When an AI system confidently extracts ‘Party A,’ ‘the plaintiff,’ and ‘the aforementioned party’ as three separate entities from a single legal paragraph — all referring to the same organisation — the knowledge graph becomes unusable.
當一個 AI 系統信誓旦旦地從同一段法律文字中,把「甲方 (Party A)」、「原告 (the plaintiff)」和「前述當事人 (the aforementioned party)」抽取成三個各自獨立的實體(entity)——而它們其實全都指向同一個組織——這個知識圖譜 (Knowledge Graph) 就變得毫無用處了。
Despite GPT-5’s impressive capabilities in text generation and reasoning, building reliable knowledge graphs from unstructured text remains a fundamental challenge — one that reveals critical gaps between how language models work and what structured knowledge extraction requires.
儘管 GPT-5 在文字生成與推理方面展現出令人驚艷的能力,但要從非結構化文字 (unstructured text) 中建立可靠的知識圖譜,仍是一項根本性的挑戰——它揭露了語言模型運作方式與結構化知識抽取需求之間的關鍵落差。
During my PhD research on extracting knowledge graphs from legal documents, I discovered that successful KG generation isn’t just about avoiding hallucinations.
在我攻讀博士、研究如何從法律文件中抽取知識圖譜的過程中,我發現成功的知識圖譜 (KG) 生成並不只是要避免幻覺 (hallucination) 而已。
It requires understanding the architectural tradeoffs between model types, defining what ground truth means for your domain, and knowing when extracted graphs need augmentation for downstream tasks.
它還需要你理解不同模型類型之間的架構取捨、為你的領域定義何謂真實標準 (ground truth),並知道何時抽取出來的圖譜需要進行增強 (augmentation) 以應付下游任務 (downstream task)。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸的圖片
An artificial intelligence model, thinking about the knowledge graph it will provide as answer (and the many flaws it will contain). Image generated with nano banana pro.
一個人工智慧模型,正在思考它將作為答案提供的知識圖譜(以及其中將包含的諸多缺陷)。圖片由 nano banana pro 生成。
This matters particularly for Retrieval Augmented Generation (RAG) systems and knowledge base population, where structural integrity and semantic consistency are non-negotiable. As GraphRAG and similar architectures enter production environments, practitioners need to understand these foundational concepts before choosing extraction approaches.
這一點對於檢索增強生成 (Retrieval Augmented Generation, RAG) 系統與知識庫填充 (knowledge base population) 尤其重要,因為在這些情境中,結構完整性與語意一致性是沒有妥協餘地的。隨著 GraphRAG 及類似架構進入正式生產環境 (production environment),從業者在選擇抽取方法之前,必須先理解這些基礎概念。
In this post, I’ll explain the core challenges in automated knowledge graph generation — why generative models struggle with structured extraction, how discriminative alternatives compare, and what defines a high-quality knowledge graph for production systems.
在這篇文章中,我會說明自動化知識圖譜生成的核心挑戰——為什麼生成式模型 (generative model) 難以勝任結構化抽取、判別式 (discriminative) 替代方案相比之下如何、以及對生產系統而言,什麼才構成一個高品質的知識圖譜。
This foundation will prepare you for the follow-up post, where I’ll demonstrate how Google’s LangExtract addresses these challenges with a hands-on implementation for paragraph-level extraction.
這些基礎將為後續文章做好準備,在那篇文章中,我會示範 Google 的 LangExtract 如何透過一個段落層級抽取 (paragraph-level extraction) 的實作範例來應對這些挑戰。
📌 Key Takeaways / 📌 重點摘要¶
- Understand why LLMs struggle with structured KG extraction
-
理解為什麼大型語言模型 (LLM) 難以進行結構化的知識圖譜抽取
-
Learn the difference between asserted and augmented knowledge graphs
-
學會斷言型 (asserted) 知識圖譜與增強型 (augmented) 知識圖譜之間的差異
-
Discover when to use discriminative vs. generative models
-
了解何時該使用判別式模型、何時該使用生成式模型
-
Explore 5 augmentation strategies with practical tradeoffs
- 探索 5 種增強策略及其實務上的取捨
Why Language Models Struggle with Knowledge Graph Extraction / 為什麼語言模型難以進行知識圖譜抽取¶
Let’s start by examining why even state-of-the-art models struggle with structured extraction. The challenge extends far beyond hallucinations — it involves fundamental mismatches between how language models generate text and the requirements of knowledge graphs.
讓我們先來探討,為什麼即使是最先進 (state-of-the-art) 的模型也難以勝任結構化抽取。這項挑戰遠遠不只是幻覺問題——它牽涉到語言模型生成文字的方式與知識圖譜需求之間的根本性錯配。
Generative models face several interconnected problems when building knowledge graphs:
生成式模型在建立知識圖譜時,會面臨好幾個彼此相關的問題:
- Entity disambiguation: The same entity appears multiple times with different phrasings, and naive extraction misses coreferences, fragmenting the graph
-
實體消歧 (entity disambiguation):同一個實體會以不同措辭多次出現,而粗淺的抽取方式會漏掉共指 (coreference) 關係,使圖譜變得支離破碎
-
Compositional entities: Terms like “City of Mexico” refer to nested concepts (both city and country), requiring hierarchical representation
-
複合實體 (compositional entities):像「墨西哥城 (City of Mexico)」這樣的詞彙指涉的是巢狀概念(同時是城市與國家),需要以階層化方式來表示
-
Hallucination at scale: Probabilistic generation produces plausible but false entities and relationships, especially with larger texts that need to be processed in sequence.
-
大規模的幻覺:機率式 (probabilistic) 生成會產生看似合理卻是虛假的實體與關係,尤其是在需要依序處理的較長文字中。
-
Context-dependent relationships: Many entity connections only make sense with full document context, but processing entire documents amplifies hallucination rates.
- 依賴上下文的關係:許多實體之間的連結,唯有在完整的文件上下文 (context) 下才說得通,但處理整份文件又會放大幻覺發生的比率。
In my legal document analysis, I observed this firsthand: even within a single paragraph, the model would identify “Party A” as a single entity and then treat subsequent references, such as “the aforementioned party,” as separate entities — despite all of them referring to the same organisation.
在我進行法律文件分析時,親眼見證了這一點:即使是在同一個段落內,模型會把「甲方 (Party A)」辨識為單一實體,然後又把後續出現的指稱,例如「前述當事人 (the aforementioned party)」,當作另外的獨立實體——儘管它們全都指向同一個組織。
This fragmentation within individual paragraphs made the resulting graphs noisy and required extensive post-processing to correctly represent the ground truth.
這種發生在單一段落內部的碎片化,使得產出的圖譜充滿雜訊,必須進行大量的後處理 (post-processing),才能正確地呈現真實標準。
Some practitioners process text in smaller chunks to reduce hallucinations, but this creates relationship loss and entity duplication. Even at the paragraph level, important entity connections can span multiple sentences, and aggressive chunking to the sentence level destroys these dependencies entirely. Moreover, it becomes more costly as the model must run multiple inference passes to process the same content.
有些從業者會把文字切成較小的區塊 (chunk) 來處理,以減少幻覺,但這會造成關係流失與實體重複。即使在段落層級,重要的實體連結也可能橫跨多個句子,而激進地把文字切到句子層級,會徹底破壞這些依賴關係。此外,由於模型必須對相同內容執行多次推論 (inference),成本也會隨之提高。
The context loss is a problem that increases with smaller contexts — it’s problematic at paragraph level and even worse at sentence level
上下文流失是一個會隨著上下文縮小而加劇的問題——在段落層級就已經有問題,到了句子層級則更糟
These limitations in generative architectures raise an important question: are there alternative model types better suited for structured extraction?
生成式架構的這些限制引出了一個重要問題:有沒有其他類型的模型更適合進行結構化抽取?
Discriminative vs. Generative Models for Knowledge Graph Extraction / 知識圖譜抽取:判別式模型對上生成式模型¶
Discriminative language models — those with bidirectional attention trained on masked language modelling — offer a compelling alternative for knowledge graph extraction.
判別式語言模型——也就是那些採用雙向注意力 (bidirectional attention)、以遮罩語言建模 (masked language modelling) 訓練而成的模型——為知識圖譜抽取提供了一個極具吸引力的替代方案。
Why this advantage? Discriminative models excel at token and sequence classification. Named entity recognition can be framed as token-level classification over the input sequence, eliminating the generation step entirely.
這個優勢從何而來?判別式模型擅長詞元 (token) 與序列分類。命名實體辨識 (named entity recognition) 可以被建構成針對輸入序列的詞元層級分類問題,從而完全省去了生成這一步驟。
Detecting named entities can be handled as a token classification, eliminating the generation process
偵測命名實體可以當作一種詞元分類來處理,省去整個生成流程
This architectural fit makes them not only more accurate for structured extraction but also efficient enough for edge deployment — a BERT-based model can run on modest hardware while GPT-5 requires substantial compute resources.
這種架構上的契合,使它們不僅在結構化抽取上更為準確,也夠有效率,足以進行邊緣部署 (edge deployment)——一個基於 BERT 的模型可以在普通的硬體上運行,而 GPT-5 卻需要可觀的運算資源。
The tradeoff is flexibility:
代價則是彈性:
- Discriminative models require task-specific fine-tuning on domain data, but achieve better performance than naïve approaches using generative language models.
-
判別式模型需要在領域資料上進行針對特定任務的微調 (fine-tuning),但相較於使用生成式語言模型的粗淺做法,它們能達到更好的效能。
-
Generative models, by contrast, can be adapted through in-context learning with prompts and few-shot examples, requiring no additional training.
- 相對地,生成式模型可以透過情境學習 (in-context learning),搭配提示 (prompt) 與少樣本 (few-shot) 範例來進行調適,不需要額外訓練。
For legal document analysis, this means choosing between a fine-tuned discriminator (higher accuracy, domain-locked) and a prompted generative model (lower accuracy, highly adaptable).
對於法律文件分析來說,這意味著要在以下兩者之間做抉擇:經過微調的判別式模型(準確度較高,但被鎖定在特定領域),以及透過提示驅動的生成式模型(準確度較低,但高度可調適)。
This efficiency-versus-flexibility tradeoff shapes a fundamental question: what kind of knowledge graph are we actually trying to build?
這種「效率對上彈性」的取捨,引出了一個根本性的問題:我們究竟想建立的是什麼樣的知識圖譜?
Regardless of model choice, successful extraction requires starting with a solid foundation — what researchers call an asserted knowledge graph that represents ground truth from the source text. This foundation becomes critical when iterative refinement is needed.
無論選擇哪一種模型,成功的抽取都必須從一個穩固的基礎開始——也就是研究人員所稱的斷言型知識圖譜 (asserted knowledge graph),它代表了源文字中的真實標準。當你需要進行迭代式精修 (iterative refinement) 時,這個基礎就變得至關重要。
Asserted Knowledge Graphs: Your Verifiable Foundation / 斷言型知識圖譜:你可驗證的基礎¶
An asserted knowledge graph represents only the explicit information stated in the source text — no inference, no external knowledge, just what’s directly present. In our case, the source is the text itself, making this graph the verifiable ground truth for that document.
斷言型知識圖譜只呈現源文字中明確陳述的資訊——不做推論、不引入外部知識,純粹只有直接存在於文字中的內容。在我們的案例裡,來源就是文字本身,因此這個圖譜便是該文件可驗證的真實標準。
Creating an asserted knowledge graph requires three core tasks:
建立一個斷言型知識圖譜需要三項核心任務:
- Entity Recognition: Identifying and classifying key spans like persons, organisations, dates, or domain-specific terms.
-
實體辨識 (Entity Recognition):辨識並分類出關鍵的文字跨度 (span),例如人物、組織、日期或領域專屬術語。
-
Relation Extraction: Finding explicit connections between entities.
-
關係抽取 (Relation Extraction):找出實體之間明確的連結。
-
Coreference Resolution: Linking different mentions of the same entity to a single node.
- 共指消解 (Coreference Resolution):將同一實體的不同指稱連結到單一節點 (node) 上。
These tasks align naturally with the strengths of discriminative models in token and sequence classification — which is why specialised BERT-based systems often tackle them separately.
這些任務恰好與判別式模型在詞元與序列分類上的強項自然契合——這也是為什麼專門的、基於 BERT 的系統,經常會把它們分開來各別處理。
However, this intuitive pipeline approach introduces a critical problem.
然而,這種看似直覺的管線式 (pipeline) 做法,卻帶來了一個關鍵問題。
The Pipeline Problem: How Accuracy Drops Dramatically / 管線式問題:準確度如何急遽下降¶
These tasks are typically performed sequentially: extract entities, then detect relations, then resolve coreferences. However, this multi-stage pipeline accumulates errors at each step.
這些任務通常是依序執行的:先抽取實體,再偵測關係,然後消解共指。然而,這種多階段管線會在每一步累積錯誤。
A 90% accurate entity recognizer feeding into a 90% accurate relation extractor yields only 81% overall accuracy — and that’s before coreference resolution introduces additional errors…
一個準確度 90% 的實體辨識器,把結果餵給一個準確度 90% 的關係抽取器,整體準確度只剩 81%——而這還是在共指消解引入額外錯誤之前的數字……
Error propagation explains why modern approaches favour end-to-end models that generate the graph in one step
錯誤傳播 (error propagation) 解釋了為什麼現代的做法偏好採用端到端 (end-to-end) 模型,一步就生成整個圖譜
A single language model generating the complete graph structure in one pass avoids the compounding failures of chained specialised models, even if each specialised component performs better on its isolated subtask.
由單一語言模型在一次推論中生成完整的圖譜結構,可以避免串接多個專用模型所造成的錯誤疊加——即使每個專用元件在它各自孤立的子任務上表現更好,仍是如此。
Why Asserted Graphs Are Non-Negotiable for Production / 為什麼斷言型圖譜對生產環境而言不容妥協¶
The asserted knowledge graph serves as your verifiable baseline. When downstream tasks require additional information — implicit relationships, connections to external knowledge bases, or domain-specific augmentation — you can expand from this trusted foundation rather than questioning the entire graph’s validity.
斷言型知識圖譜扮演了你可驗證的基準 (baseline)。當下游任務需要額外資訊時——例如隱含關係、與外部知識庫的連結,或領域專屬的增強——你可以從這個值得信賴的基礎上向外擴展,而不必去質疑整個圖譜的有效性。
This becomes critical for production systems, where explainability and debugging depend on knowing which information came directly from the source rather than from inference or augmentation.
這對生產系統而言至關重要,因為在這類系統中,可解釋性 (explainability) 與除錯都仰賴於你能分辨哪些資訊是直接來自源文字,而非來自推論或增強。
However, this verifiable foundation alone may not be sufficient for many real-world applications, which is where augmentation strategies become necessary.
然而,光是這個可驗證的基礎,對許多真實世界的應用來說可能還不夠,這正是增強策略派上用場的地方。
Augmenting the Asserted Knowledge Graph / 增強斷言型知識圖譜¶
The asserted knowledge graph, on its own, is often insufficient for real-world applications. After extracting ground truth from legal documents , I consistently encountered three fundamental limitations:
斷言型知識圖譜單憑自身,往往不足以應付真實世界的應用。在從法律文件中抽取真實標準之後,我一再遇到三項根本性的限制:
- Disconnected components: Many graphs contain isolated entity clusters with no connecting paths, limiting traversability
-
不連通的元件 (disconnected components):許多圖譜中包含彼此孤立的實體叢集,之間沒有連通的路徑,限制了可遍歷性 (traversability)
-
Missing implicit knowledge: Real documents assume a shared context that isn’t explicitly stated.
-
缺失的隱含知識:真實的文件往往預設了一個共享的上下文,而這個上下文並未被明確寫出。
-
External alignment needs: Entities require normalisation to broader knowledge bases for downstream integration.
- 對外部對齊的需求:為了下游整合,實體需要被正規化 (normalisation) 到更廣泛的知識庫中。
These gaps necessitate strategic augmentation approaches.
這些缺口使得策略性的增強做法成為必要。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸的圖片
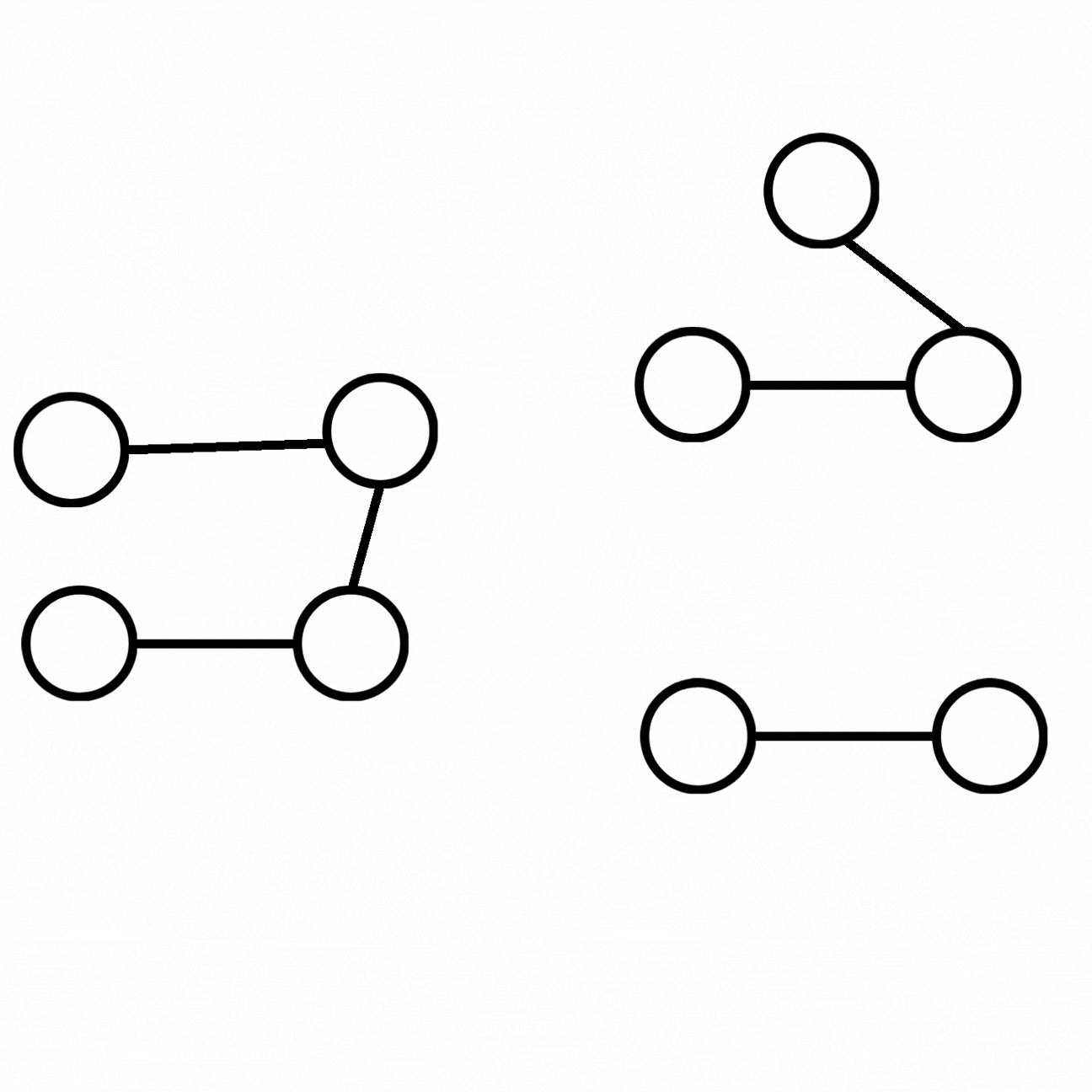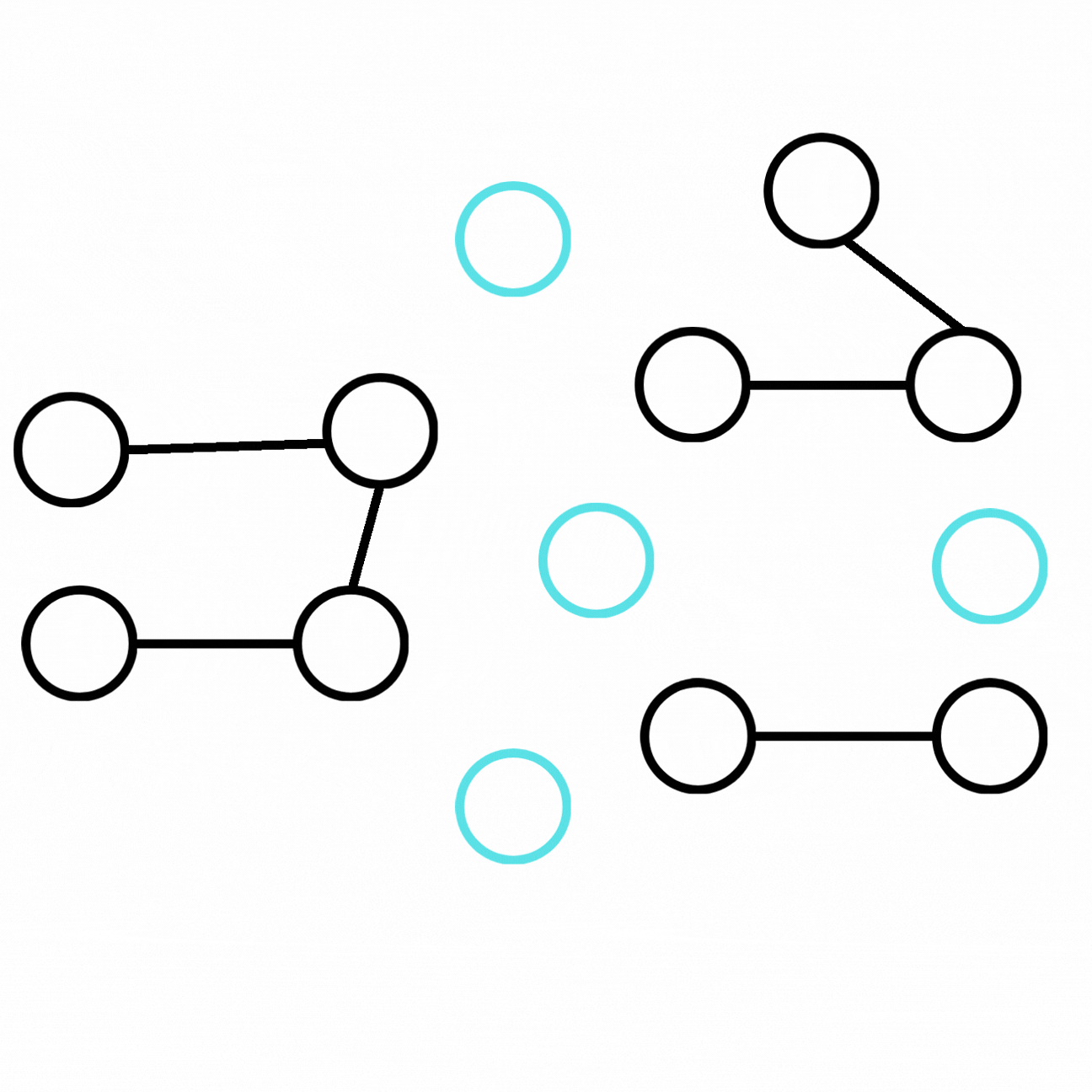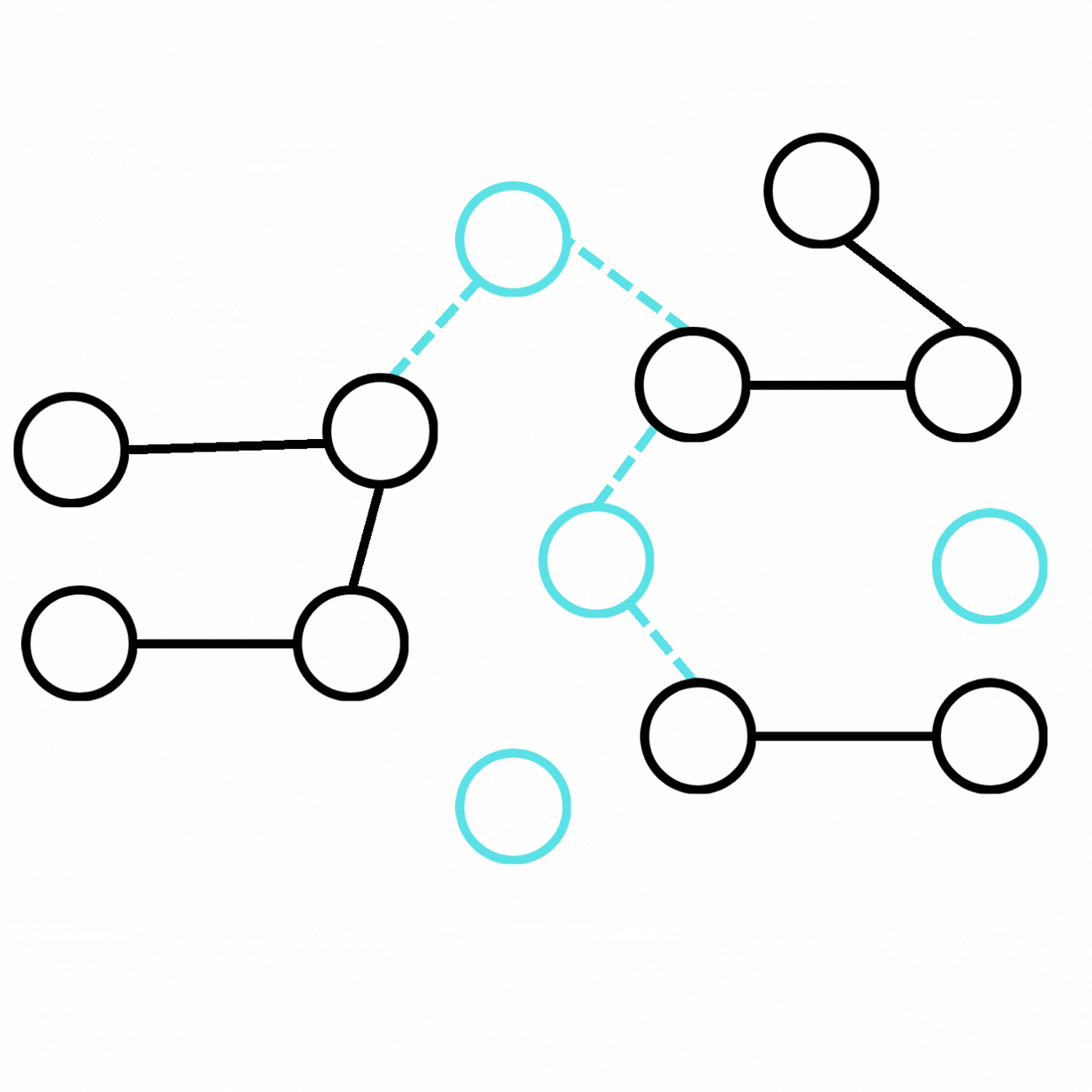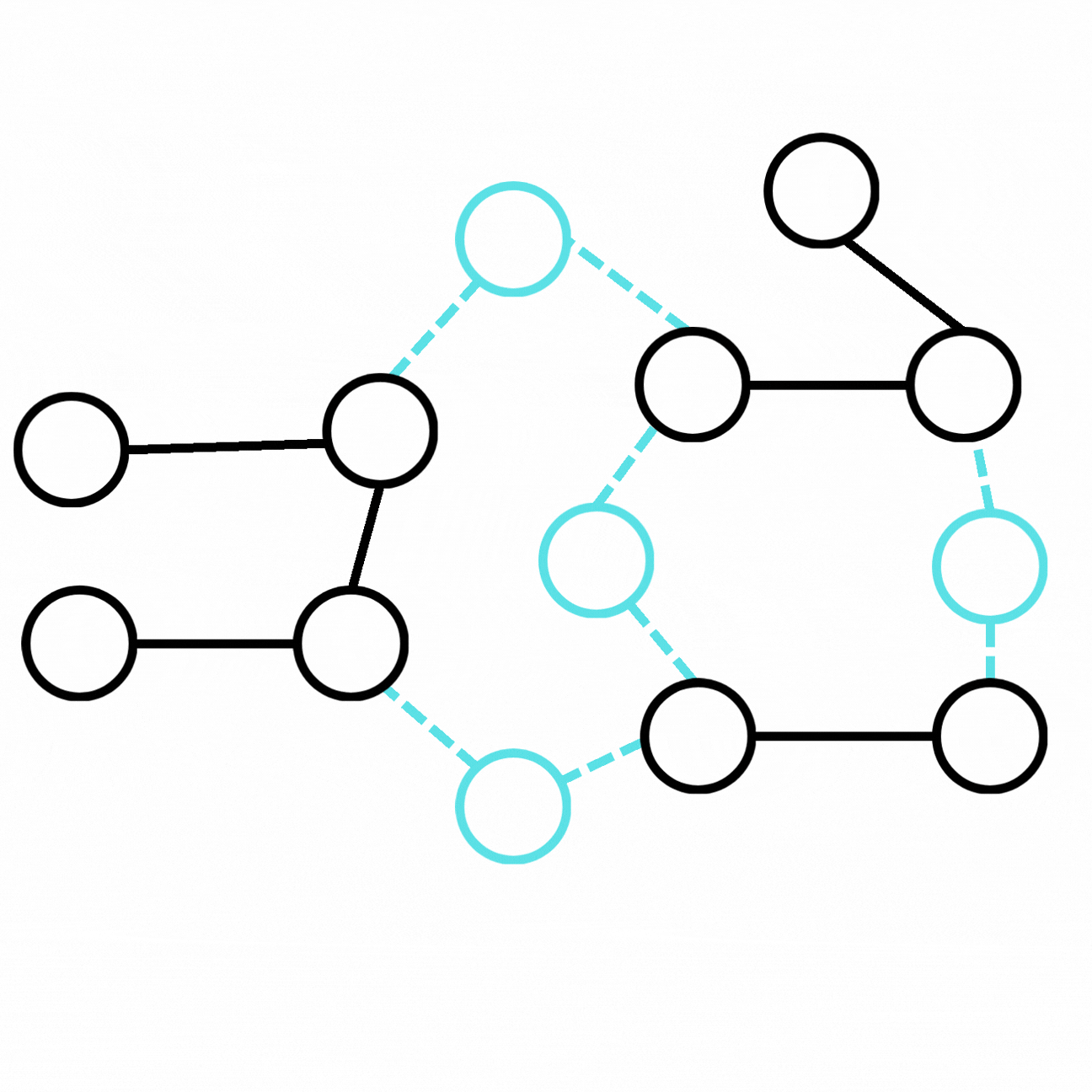
We can obtain an augmented graph from the ground-truth graph by adding new entities and relations connected to our initial graph.
我們可以透過在初始圖譜上添加與之相連的新實體與新關係,從真實標準圖譜得到一個增強後的圖譜。
Taxonomic Augmentation: Building Knowledge Hierarchies / 分類學式增強:建構知識階層¶
The downstream task might benefit from intuitive relations that are easy to automatically generate (“is a,” “located in,” “part of”, etc). For legal documents, this includes inferring standard roles like “judge,” “plaintiff,” or “legal case” from contextual clues.
下游任務可能會受益於容易自動生成的直覺式關係(如「is a(是一種)」、「located in(位於)」、「part of(屬於……的一部分)」等)。以法律文件為例,這包括從上下文線索中推論出像是「法官 (judge)」、「原告 (plaintiff)」或「法律案件 (legal case)」這類標準角色。
Hierarchical relationships prove particularly valuable — adding taxonomic connections that organise entities into ontological structures. For instance, establishing that [employment contract, is a, legal contract] or [Party A, is a corporation] creates navigable hierarchies from flat lists of entities.
階層式關係被證明特別有價值——它能加入分類學式的連結,把實體組織成本體論 (ontological) 結構。舉例來說,建立 [僱傭合約, is a, 法律合約] 或 [甲方, is a 公司] 這樣的關係,就能把扁平的實體清單轉化為可供瀏覽導覽的階層。
Generative language models can handle this augmentation when constrained to predefined relation vocabularies — unconstrained generation risks hallucinations and might collapse into standard hierarchical relationships more typical of common knowledge than of specific domains.
當生成式語言模型被約束在預先定義好的關係詞彙之內時,它們能夠勝任這種增強工作——無約束的生成則有產生幻覺的風險,並且可能退化成那種較貼近常識、而非特定領域的標準階層關係。
Rule-Based Augmentation / 規則式增強¶
Another approach leverages logical rules to infer new facts from existing patterns. Simple rules like “if Entity A employs Entity B, then Entity A is an organisation” codify domain knowledge explicitly.
另一種做法是運用邏輯規則,從既有的模式中推論出新的事實。像「若實體 A 僱用實體 B,則實體 A 是一個組織」這樣的簡單規則,便把領域知識明確地編碼了下來。
Multi-hop rules enable more complex inference: “if case A violates article 5, and article 5 belongs to regulation R, then case A also violates regulation R.” These chained inferences can dramatically increase graph connectivity and reveal implicit relationships.
多跳 (multi-hop) 規則則能進行更複雜的推論:「若案件 A 違反第 5 條,而第 5 條隸屬於法規 R,則案件 A 也違反法規 R。」這類串接式的推論能大幅提升圖譜的連通性 (connectivity),並揭露出隱含的關係。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸的圖片

Example of a Domain specific rule for augmenting the relations in the asserted graph.
一個用於增強斷言型圖譜中關係的領域專屬規則範例。
The tradeoff is that rule-based augmentation requires expert knowledge to define valid inference patterns.
代價是,規則式增強需要專家知識來定義出有效的推論模式。
Unlike learned approaches, rules won’t generalise beyond what domain experts explicitly encode — but they also won’t hallucinate invalid relationships, making them reliable when correctness is paramount.
與學習式的做法不同,規則無法推廣到領域專家明確編碼以外的範圍——但它們也不會幻想出無效的關係,這使得它們在正確性至上的情況下相當可靠。
Link Prediction with Knowledge Base Alignment / 結合知識庫對齊的連結預測¶
One approach is identifying missing relations within the existing entity set, thereby increasing graph connectivity without adding new nodes. This can be accomplished by training models on link prediction over domain-specific knowledge bases.
其中一種做法是辨識出現有實體集合內部所缺失的關係,藉此在不增加新節點的前提下提升圖譜的連通性。這可以透過在領域專屬的知識庫上訓練模型進行連結預測 (link prediction) 來達成。
The model trains on triples [Entity A — Relation — Entity B] and learns to infer whether a relation exists between any two entities, and if so, what type.
模型以三元組 [實體 A — 關係 — 實體 B] 進行訓練,並學會推論任意兩個實體之間是否存在關係,若存在,又是哪一種類型。
Alternatively, generative language models can predict missing relations through prompting, though this approach is more prone to hallucinations and requires carefully defining valid relation subsets.
或者,生成式語言模型也可以透過提示來預測缺失的關係,只不過這種做法更容易產生幻覺,而且需要謹慎地定義出有效的關係子集。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸的圖片

Training and inference process of an entity linking model. The models trained this way tend to use diverse geometric spaces encoded in their loss functions to capture complex relations among entities, or through language models.
一個實體連結 (entity linking) 模型的訓練與推論流程。以這種方式訓練出來的模型,往往會運用編碼在其損失函數 (loss function) 中的多種幾何空間,來捕捉實體之間的複雜關係,或是透過語言模型來達成。
Source Context Preservation / 源上下文保留¶
Another approach augments the graph by preserving the original source structure.
另一種做法則是透過保留原始的來源結構來增強圖譜。
This involves creating nodes that represent text spans — sentences, paragraphs, or entire documents — and implementing them in two ways: either connecting these nodes to their related entities (increasing overall graph connectivity) or creating a nested hierarchy in which higher-level text nodes contain the subgraphs extracted from their content.
這牽涉到建立代表文字跨度(句子、段落或整份文件)的節點,並以兩種方式來實作它們:要嘛把這些節點連接到它們相關的實體(提升整體圖譜的連通性),要嘛建立一個巢狀階層,讓較高層級的文字節點包含從其內容中抽取出來的子圖 (subgraph)。
This augmentation adds valuable context without introducing factual errors, since you’re representing what actually exists in the source rather than inferring new knowledge.
這種增強在不引入事實錯誤的前提下,加入了有價值的上下文,因為你呈現的是來源中實際存在的內容,而非推論出新的知識。
When an entity appears in multiple contexts, these provenance nodes reveal usage patterns and semantic relationships that weren’t explicitly stated in individual entity connections.
當一個實體出現在多個上下文中時,這些來源溯源 (provenance) 節點便能揭露出那些在個別實體連結中未被明確陳述的使用模式與語意關係。
This way, you can trace any entity or relationship back to its exact source location, understanding not just what was extracted but where it came from and in what context it appeared.
如此一來,你便能把任何實體或關係追溯回它確切的來源位置,不只理解抽取了什麼,更理解它從何而來、以及它是在什麼樣的上下文中出現的。
Note that simpler implementations can achieve similar traceability by storing source metadata (document IDs, sentence positions) directly on entity and relation nodes during graph construction, thereby avoiding the overhead of additional structural nodes.
請注意,較簡單的實作方式也能達到類似的可追溯性:在建構圖譜的過程中,直接把來源後設資料 (metadata)(如文件 ID、句子位置)儲存在實體節點與關係節點上,從而避免了額外結構節點所帶來的開銷。
The choice between metadata and explicit nodes depends on whether your downstream task benefits from treating text spans as queryable graph entities themselves.
要在後設資料與明確節點之間做選擇,取決於你的下游任務是否能受益於把文字跨度本身當作可查詢的圖譜實體來處理。
Topic Clustering for Connectivity / 以主題分群提升連通性¶
Disconnected components remain problematic for graph traversal and global queries. Topic-based clustering addresses this by creating bridge nodes that connect related entities.
不連通的元件對於圖譜遍歷與全域查詢來說始終是個問題。基於主題的分群 (topic-based clustering) 透過建立連接相關實體的橋接節點 (bridge node) 來解決這個問題。
A straightforward approach uses predefined categories: train a classification model on domain-specific topics (e.g., for legal documents: “employment law,” “intellectual property,” “contract disputes”), then create topic nodes that connect all entities from documents within each category.
一種直截了當的做法是使用預先定義好的類別:在領域專屬的主題上訓練一個分類模型(例如針對法律文件:「勞動法」、「智慧財產權」、「合約糾紛」),然後建立主題節點,把每個類別下文件中的所有實體都連接起來。
This method is interpretable and works well for domains with stable taxonomies.
這種方法具有可解釋性,並且在分類體系穩定的領域中運作良好。
More sophisticated approaches, such as GraphRAG, use hierarchical community detection algorithms to automatically discover entity clusters at multiple granularities, though these require additional computation.
更精密複雜的做法,例如 GraphRAG,會運用階層式社群偵測 (hierarchical community detection) 演算法,在多種粒度 (granularity) 下自動發現實體叢集,只不過這些做法需要額外的運算。
Press enter or click to view image in full size
按下 Enter 或點擊以檢視完整尺寸的圖片
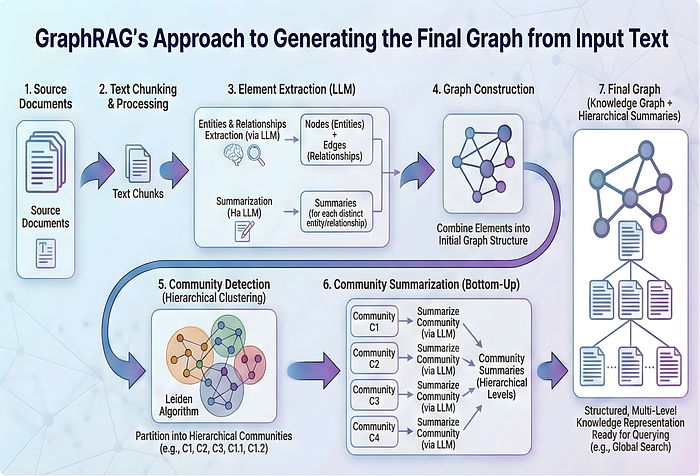
Infographic showing the entire process involved when using GraphRAG to generate the queryable knowledge.
一張資訊圖表,展示使用 GraphRAG 來生成可查詢知識時所涉及的完整流程。
The choice between predefined classification and automated discovery depends on whether your domain has well-established categories or benefits from emergent pattern detection.
要在預先定義的分類與自動化發現之間做選擇,取決於你的領域是否已有完善建立的類別,抑或能受益於對湧現模式 (emergent pattern) 的偵測。
Choosing the Right Augmentation Strategy / 選擇正確的增強策略¶
In my legal document work with LangExtract, I found that a straightforward approach proved sufficient: using the same generative model to infer implicit entities and relations from both the ground truth graph and the original text.
在我使用 LangExtract 處理法律文件的工作中,我發現一個直截了當的做法就已足夠:使用同一個生成式模型,同時從真實標準圖譜與原始文字中推論出隱含的實體與關係。
This augmentation strategy — constrained to predefined relation types — produced knowledge graphs that effectively captured the semantic structure needed for downstream GNN-based classification tasks.
這個被約束在預先定義關係類型之內的增強策略,產出了能有效捕捉語意結構的知識圖譜,足以滿足下游基於圖神經網路 (GNN) 的分類任務所需。
The optimal augmentation strategy depends entirely on your downstream application. For tasks requiring complex reasoning across disconnected components, clustering techniques provide the necessary connectivity.
最佳的增強策略完全取決於你的下游應用。對於需要跨越不連通元件進行複雜推理的任務,分群技術能提供所需的連通性。
For classification or entity-focused tasks, selective inference of implicit knowledge may suffice. For high-stakes domains where correctness trumps coverage, rule-based approaches ensure reliability.
對於分類或聚焦於實體的任務,有選擇性地推論隱含知識或許就已足夠。對於正確性勝過涵蓋率的高風險領域,規則式做法則能確保可靠性。
Before augmentation:
“Party A” (entity)
“Employment Contract” (entity)
After adding taxonomic relations:
“Party A” → [is a] → “Corporation” → [is a] → “Legal Entity”
“Employment Contract” → [is a] → “Legal Contract” → [is a] → “Document”
增強之前:
「甲方」(實體)
「僱傭合約」(實體)
加入分類學式關係之後:
「甲方」→ [is a] →「公司」→ [is a] →「法律實體」
「僱傭合約」→ [is a] →「法律合約」→ [is a] →「文件」
Trial and error reveals that the most effective solution often defies initial intuition — start with your asserted foundation, then iterate on augmentation until the graph serves its intended purpose.
反覆試驗會揭示出,最有效的解決方案往往違背最初的直覺——先從你的斷言型基礎開始,然後不斷迭代增強,直到圖譜能達成它預期的目的為止。
What’s Next: A Practical Framework with Hands-On Code / 接下來:一個附帶實作程式碼的實用框架¶
Understanding these augmentation strategies is one thing — implementing them reliably is another. In the next post, I’ll demonstrate a practical approach to automatic knowledge graph augmentation using LangExtract for initial extraction, then iteratively augmenting the asserted graph with the same language model to infer missing entities and relations. All with hands-on code you can run yourself.
理解這些增強策略是一回事——能可靠地把它們實作出來又是另一回事。在下一篇文章中,我會示範一套自動化知識圖譜增強的實用做法:先使用 LangExtract 進行初始抽取,接著再用同一個語言模型迭代地增強斷言型圖譜,以推論出缺失的實體與關係。全部都附帶你可以自己動手執行的實作程式碼。
The framework addresses the key challenge we’ve discussed: eliminate disconnected components without introducing excessive hallucinations.
這套框架要解決的正是我們先前討論過的關鍵挑戰:在不引入過多幻覺的前提下,消除不連通的元件。
Starting with LangExtract’s paragraph-level extraction of the asserted graph, I’ll show how to use the same LLM in an iterative refinement loop — prompting it to identify and fill gaps until the graph achieves full connectivity, all while maintaining traceability back to source text.
從 LangExtract 對斷言型圖譜進行的段落層級抽取開始,我會示範如何在一個迭代式精修迴圈中使用同一個大型語言模型——透過提示,讓它辨識並填補缺口,直到圖譜達成完全連通為止,且全程維持可回溯到源文字的可追溯性。
While I’ll demonstrate it on legal document analysis from my experiments, the same pattern applies across domains: extract your asserted foundation, then iteratively prompt for missing connections using domain-appropriate constraints.
雖然我會以我實驗中的法律文件分析作為示範,但同樣的模式適用於各個領域:先抽取你的斷言型基礎,然後運用適合該領域的約束,迭代地透過提示來補上缺失的連結。
Whether you’re working with medical records, scientific literature, or business documents, the framework adapts to your needs just by using new prompts for those domains.
無論你處理的是病歷、科學文獻還是商業文件,這套框架只要為那些領域換上新的提示,就能適應你的需求。
What’s your biggest challenge with knowledge graph extraction? Share your experience in the comments, and I’ll address specific questions in the follow-up post with hands-on code.
你在知識圖譜抽取上遇到的最大挑戰是什麼?歡迎在留言區分享你的經驗,我會在附帶實作程式碼的後續文章中回應一些具體的問題。
Follow me for Part 2 next week, where we’ll implement this framework with LangExtract and demonstrate iterative graph augmentation on real legal documents.
下週請追蹤我的第二部分,屆時我們會用 LangExtract 實作這套框架,並在真實的法律文件上示範迭代式的圖譜增強。
Read more on my series using LLMs with graphs:
更多內容請見我「用大型語言模型搭配圖譜」的系列文章:
[## From Rows to Relationships: turn your SQL into a graph.
Most of your data lives in relational databases. Most of your interesting questions live in the connections: who…¶
medium.com](https://medium.com/data-science-collective/from-rows-to-relationships-turn-your-sql-into-a-graph-16436e9832e9?source=post_page-----dcb029f35f5b---------------------------------------)
[## From Rows to Relationships:把你的 SQL 轉化為圖譜。
你大部分的資料都存放在關聯式資料庫中。但你大部分有趣的問題,都藏在那些連結裡:誰……¶
medium.com](https://medium.com/data-science-collective/from-rows-to-relationships-turn-your-sql-into-a-graph-16436e9832e9?source=post_page-----dcb029f35f5b---------------------------------------)
Understanding should not be a luxury reserved for specialists. My goal is to make frontier AI and machine learning research accessible through clear, tutorial-style explanations.
理解,不該是只保留給專家的奢侈品。 我的目標是透過清晰、教學風格的解說,讓最前沿的 AI 與機器學習研究變得人人都能親近。
If this piece helped you think more clearly about the topic, showing support with claps or a subscription genuinely helps keep this work going.
如果這篇文章幫助你把這個主題想得更清楚,那麼用拍手 (claps) 或訂閱來表達支持,真的能讓這份工作得以持續下去。
You’re always welcome to connect with me on LinkedIn, where I share more writing and ideas in the same spirit.
也隨時歡迎你在 LinkedIn 上與我聯繫,我在那裡以同樣的精神分享更多寫作與想法。