How to Extract High-Value Knowledge Graph Relationships¶
Author: QuarkAndCode
Published:
Source: https://medium.com/@QuarkAndCode/how-to-extract-high-value-knowledge-graph-relationships-36bab532d6f7
Fetched: 2026-06-07T02:00:59.267975
How to Extract High-Value Knowledge Graph Relationships¶
Press enter or click to view image in full size

Knowledge graphs are most effective when they connect facts rather than just store them. Their real value comes from relationships, such as who owns what, which product depends on which component, which disease is linked to which symptom, which author wrote which paper, which customer is tied to which account, or which document supports a business decision.
A knowledge graph relationship is usually represented as a connection between two entities. In RDF, this is commonly expressed as a subject–predicate–object triple, where the predicate describes the relationship between the subject and object. The W3C RDF specification describes this as a statement that a relationship indicated by the predicate holds between two resources.
Not every relationship you extract is worth keeping. If a graph is full of weak, duplicate, vague, or unsupported relationships, it quickly becomes cluttered. The aim is not to collect as many relationships as possible, but to focus on those that are accurate, useful, explainable, and valuable for search, analytics, recommendations, automation, or decision-making.
What Makes a Knowledge Graph Relationship “High-Value”?¶
A high-value relationship is a connection that improves the usefulness of the graph. It helps answer important questions, supports business workflows, reveals hidden patterns, or improves the accuracy of downstream systems.
For example, the relationship:
Product A — usesComponent — Battery B
is more useful than:
Product A — mentionedWith — Battery B
The first relationship gives us specific, actionable information. It can help with supply-chain analysis, compatibility checks, warranty decisions, product recommendations, and risk alerts. The second relationship shows only that the two entities appeared together, which might not be significant.
High-value relationships usually have five qualities:
They are specific. “Founded by,” “manufactured in,” “depends on,” “approved by,” and “compatible with” are stronger than vague predicates such as “related to” or “associated with.”
They are relevant to a real use case. A relationship that helps answer a customer, operational, compliance, research, or SEO question is more valuable than one that merely adds volume.
They are verifiable. A strong relationship should be traceable to a source such as a document, database row, API response, contract, scientific paper, or trusted web page. Provenance matters because users need to know where a fact came from.
They are reusable. A good relationship can support multiple queries, workflows, or applications.
They are maintained. Relationships can become stale. Job titles change, companies merge, prices shift, policies update, and scientific understanding evolves. A high-value graph needs a process for refreshing and correcting relationships over time.
Start With the Questions the Graph Must Answer¶
The best relationship extraction projects begin with questions, not tools. These are often called competency questions in ontology and knowledge graph design. They define what the graph should be able to answer.
Examples include:
Press enter or click to view image in full size
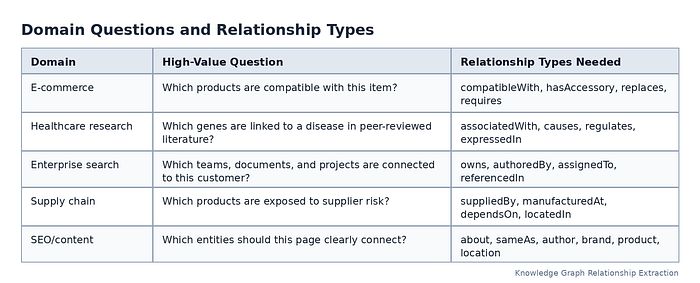
This step prevents the graph from becoming a dumping ground. If a relationship does not help answer a meaningful question, it may not be worth extracting.
Industry knowledge graphs are used in search, product understanding, social networks, question answering, and enterprise discovery. A well-known industry paper from Google Research describes knowledge graphs as structured factual knowledge used by major companies to power intelligent products and search experiences.
Build a Relationship Schema Before Extracting at Scale¶
A relationship schema defines the types of connections your graph should contain. Without a schema, extraction systems may produce many variations of the same idea:
· “works for”
· “is employed by.”
· “employee at”
· “staff member of”
· “joined the company.”
· “has employer”
These may all need to map to one canonical relationship, such as:
Person — worksFor — Organization¶
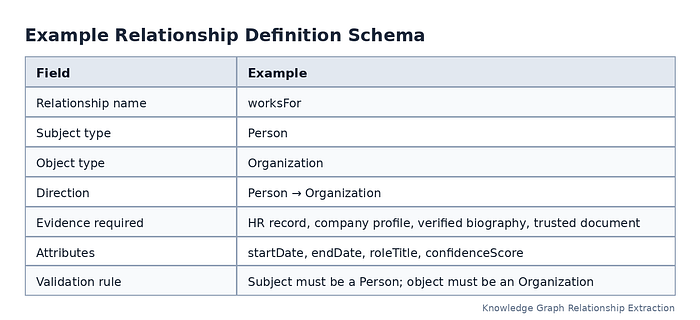
A schema does not need to be perfect at the start. It can evolve. But it should include the core relationship types, entity types, allowed directions, expected data sources, and validation rules.
A simple relationship definition might look like this:
Press enter or click to view image in full size
For semantic web and structured data projects, Schema.org can also help standardize public-facing descriptions of entities and relationships. Schema.org states that its vocabularies cover entities, relationships between entities, and actions, and that they can be expressed through formats such as RDFa, Microdata, and JSON-LD.
Choose the Right Sources for Relationship Extraction¶
High-value relationships usually come from high-quality sources. Choosing the right sources is one of the most important steps in building a knowledge graph.
Structured data sources are often the easiest to process. These include relational databases, CRM records, product catalogs, spreadsheets, APIs, data warehouses, and event logs. They usually contain explicit relationships such as customer-to-account, product-to-category, or employee-to-department.
Semi-structured sources include HTML pages, JSON files, XML documents, metadata, tables, and structured web markup. These often have clear entity attributes and relationships, but may need cleaning and normalization.
Unstructured sources include PDFs, reports, emails, contracts, manuals, research papers, news articles, transcripts, and support tickets. These are harder to process because relationships are expressed in natural language. However, they often contain the richest and most valuable knowledge.
For SEO and public web visibility, structured data is especially important. Google Search Central explains that structured data provides Google with explicit clues about a page’s meaning and can help it understand information about people, books, companies, recipes, and other entities on the web. Google also notes that JSON-LD is generally recommended when site setup allows it.
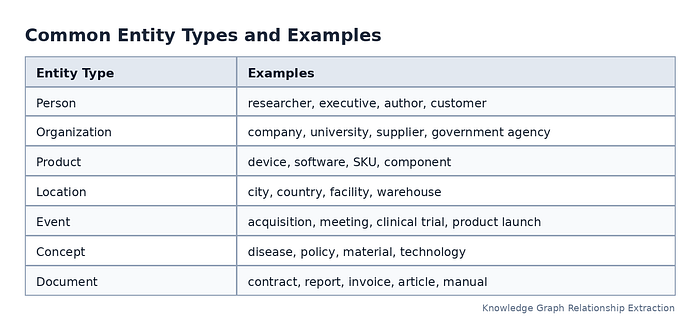
Extract Entities Before Extracting Relationships¶
Relationship extraction depends on entity extraction. A system must first recognize the things being connected before it can understand how they are connected.
Press enter or click to view image in full size
After identifying entities, the system should normalize them. “IBM,” “International Business Machines,” and “IBM Corp.” may refer to the same organization. “New York,” “NYC,” and “New York City” may need to be consolidated into a single location entity, depending on the domain.
This step is often called entity linking or entity resolution. It is essential because duplicate entities create duplicate relationships. A graph with three versions of the same company will yield fragmented, misleading results.
Use Multiple Extraction Methods, Not Just One¶
There is no one best way to extract knowledge graph relationships. The most effective pipelines usually combine rules, machine learning, language models, human review, and graph validation.
1. Rule-Based Relationship Extraction¶
Rule-based extraction works well when the language is predictable or the data is structured. For example:
· “X was founded by Y.”
· “X is headquartered in Y.”
· “X requires Y.”
· “X is compatible with Y.”
· “X reports to Y”
Rules can be created with regular expressions, dependency parsing, database mappings, or template-based patterns. They are transparent and easy to audit, but they can miss relationships expressed in unexpected ways.
Rule-based methods are useful for legal clauses, product manuals, financial filings, policy documents, and other domains where language follows repeatable patterns.
2. Open Information Extraction¶
Open Information Extraction, often called OpenIE, extracts relation triples from text without requiring every relationship type to be defined in advance. The original OpenIE research introduced a scalable approach for extracting large numbers of relational tuples from web text without manually specifying every target relation first.
Stanford CoreNLP’s OpenIE annotator, for example, extracts open-domain triples consisting of a subject, relation, and object. Its documentation describes triples such as a person being born in a place and notes that OpenIE can be useful when there is limited training data.
OpenIE is useful for discovery. It helps find possible relationships you might not have included in your original schema. However, OpenIE results often need cleaning because natural-language predicates can be inconsistent, wordy, or repetitive.
For example, OpenIE might extract:
“Battery B” — “is required for operation of” — “Product A”
A knowledge graph pipeline may need to normalize that into:
Product A — requiresComponent — Battery B
3. Supervised Relation Extraction¶
Supervised relation extraction uses labeled examples to train a model. For instance, humans may label sentences that express relationships such as:
· acquiredBy
· locatedIn
· treats
· causes
· authorOf
· manufacturedBy
· partOf
The model learns how those relationships appear in text and then predicts them in new documents.
This approach can be accurate if you have enough labeled data. The downside is cost, since creating high-quality labeled examples takes time and domain knowledge.
4. Distant Supervision¶
Distant supervision reduces the need for manual labeling by automatically generating training examples from an existing knowledge base. The classic distant supervision paper by Mintz, Bills, Snow, and Jurafsky used Freebase relations to train relation extractors from unlabeled text, offering an alternative to hand-labeled corpora.
This method is helpful if you already have a partial knowledge graph or a trusted database. It can help you scale up relation extraction, but it may also introduce noisy labels. The process should still include confidence scoring and validation.
5. LLM-Assisted Relationship Extraction¶
Large language models can help extract relationships from complex text, especially when the relationships are implied rather than expressed in a simple pattern. They can also help rewrite messy natural-language relations into canonical graph predicates.
For example, a document may say:
“Product A cannot operate unless Firmware B has been installed.”
A language model can help infer:
Product A — requires Software — Firmware B
LLMs are especially useful for candidate generation, schema mapping, summarizing evidence, and handling varied language. However, they should not be treated as the final source of truth. For high-value relationships, every extraction should be grounded in source text, checked against schema rules, and assigned a confidence score.
A practical LLM-assisted pipeline should require the model to return:
Press enter or click to view image in full size
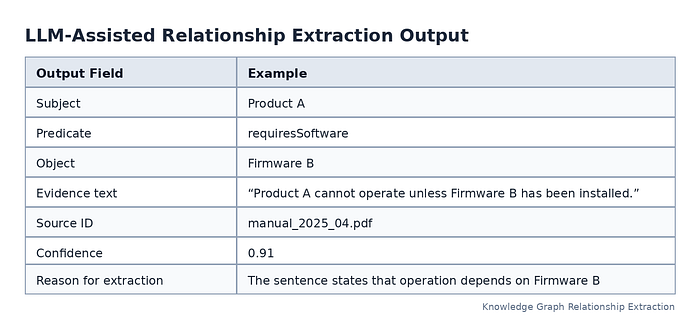
This keeps the relationship easier to explain and review.
Normalize Relationship Predicates¶
Raw extraction often produces many relationship phrases that mean the same thing. Normalization converts them into a controlled vocabulary.
For example:
Press enter or click to view image in full size
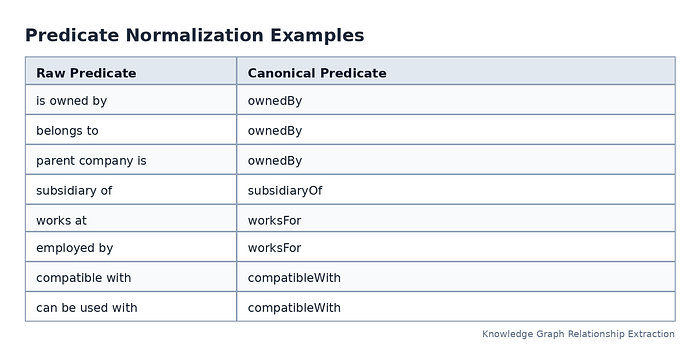
This step improves query quality. Instead of searching across dozens of near-duplicate predicates, users and applications can query one canonical relationship.
Normalization should also preserve direction. “Company A owns Company B” is not the same as “Company A is owned by Company B.” Direction errors are among the most damaging mistakes in knowledge graph construction.
Add Context to Relationships¶
Some relationships are always true, but many are only true within a specific context.
For example:
Person A — worksFor — Company B
may need context:
· role title
· department
· start date
· end date
· location
· employment status
· source document
· confidence score
Without time and context, the graph may become misleading. A person who worked for a company in 2018 may not work there today. A product that was compatible with one software version may not be compatible with the next.
Context is especially important for relationships involving employment, ownership, contracts, prices, regulations, medical evidence, scientific claims, political roles, and product compatibility.
Capture Provenance for Every Important Relationship¶
Provenance tells users where a relationship came from and how it was created. It answers questions such as:
· Which source supports this relationship?
· When was it extracted?
· Was it extracted by a rule, a model, an API, or a human?
· Has it been verified?
· What evidence does the text support?
· Has the source changed?
The W3C PROV-O specification provides a model for representing and exchanging provenance information across systems and domains. It includes classes and properties that can be specialized for different applications.
A high-value relationship should not just be stored as:
Supplier A — supplies — Component B
It should also include:
Press enter or click to view image in full size
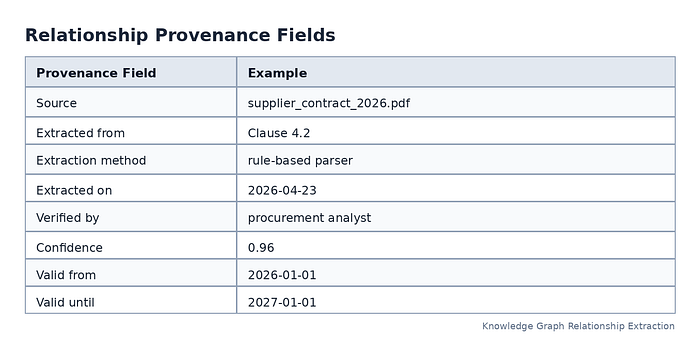
This makes the graph more trustworthy and easier to audit.
Score Relationships by Value, Not Just Confidence¶
Confidence and value are different. A relationship can be highly confident but not very useful. Another relationship may be moderately confident but extremely valuable if it affects risk, revenue, compliance, or user experience.
A good relationship scoring model should consider both.
Press enter or click to view image in full size
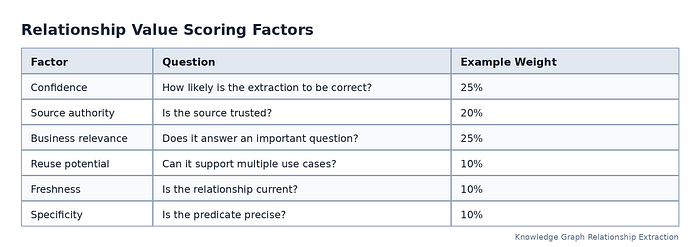
A simple scoring formula might look like this:
Relationship Value Score = Confidence + Source Authority + Use-Case Importance + Reuse + Freshness + Specificity
This score helps teams decide which relationships to review first, which to publish, and which to keep as low-confidence candidates.
Graph analytics can also help identify important entities and relationships. Centrality algorithms, for example, are commonly used to determine important nodes in a network. Neo4j’s Graph Data Science documentation lists centrality methods such as PageRank, degree centrality, closeness centrality, betweenness centrality, and eigenvector centrality.
However, being important in the graph does not mean something is true. A highly connected node might be important, but its relationships still need to be checked.
Validate Relationships Before Publishing
Validation protects the graph from incorrect facts, broken logic, and inconsistent structure.
Common validation checks include:
Press enter or click to view image in full size
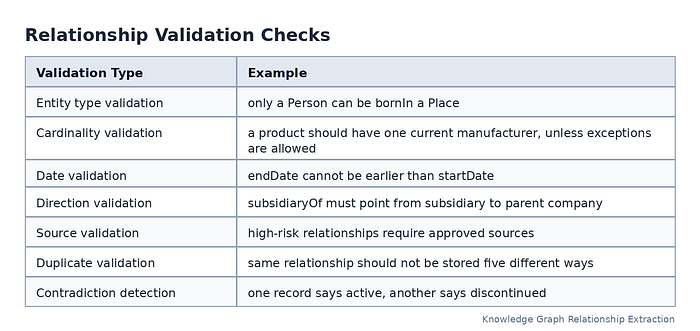
For RDF graphs, SHACL is a widely used validation language. The W3C SHACL specification defines it as a language for validating RDF graphs against conditions expressed as shapes.
Validation should happen before relationships are loaded into production. It should also continue after loading because new data can conflict with old data.
Use Human Review Where the Cost of Error Is High¶
Automation can extract relationships quickly, but human review is still important for high-stakes domains.
Human experts should review relationships involving:
· legal obligations
· medical or scientific claims
· financial risk
· regulatory compliance
· security permissions
· supplier dependencies
· public brand facts
· customer-sensitive data
Human review does not need to cover every relationship. A risk-based approach works better. Review high-value and low-confidence relationships first. Low-risk, high-confidence relationships can often be accepted automatically.
Store Relationships in a Graph-Friendly Format¶
Once extracted, normalized, scored, and validated, relationships should be stored in a format that supports graph queries.
Common options include:
Press enter or click to view image in full size
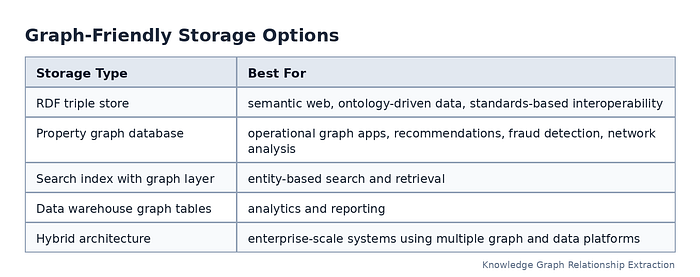
A relationship should usually include not only the subject, predicate, and object, but also details such as source, confidence, timestamps, status, and evidence.
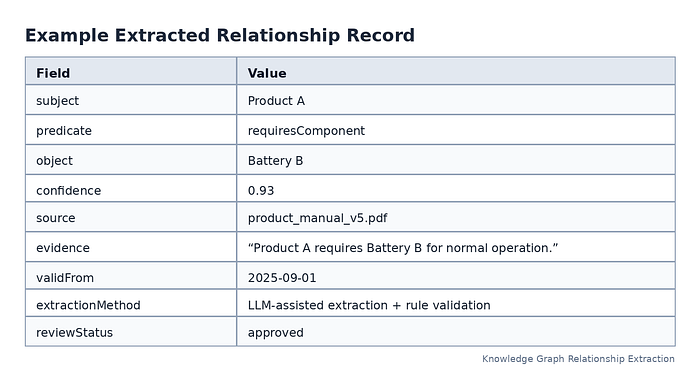
Example:
Press enter or click to view image in full size
Improve Relationship Extraction Over Time¶
Extracting knowledge graphs is not a one-time task. The best graphs get better through feedback.
Track these metrics:
Press enter or click to view image in full size
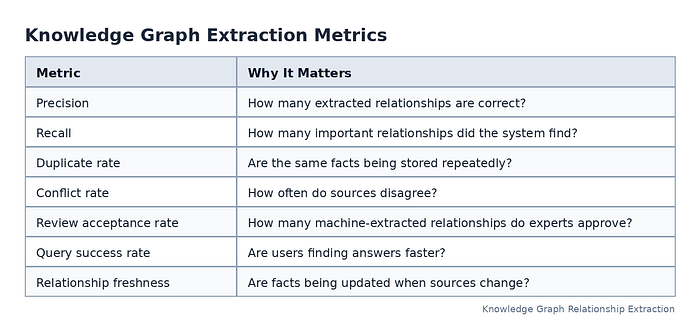
Feedback from users, analysts, search logs, and failed queries should guide the next extraction cycle. For example, if users often search for product compatibility but the graph lacks those relationships, that signals a need to improve extraction for that area.
Common Mistakes to Avoid¶
One common mistake is extracting relationships without a clear purpose. This creates a large graph that looks impressive but answers few important questions.
Another mistake is using vague predicates. “Related to” is easy to extract but hard to use. Specific relationships improve search, reasoning, filtering, and analytics.
A third mistake is ignoring provenance. A relationship without evidence is hard to trust, especially when users need to make decisions based on it.
A fourth mistake is skipping entity resolution. If the same company, product, or person appears under different names, the graph becomes fragmented.
A fifth mistake is treating AI output as final. AI can speed up extraction, but high-value relationships still need schema alignment, source checks, validation, and quality control.
Practical Workflow for Extracting High-Value Knowledge Graph Relationships¶
A strong extraction workflow looks like this:
-
Define the use case and questions the graph must answer.
-
Identify the most valuable entity and relationship types.
-
Select trusted structured, semi-structured, and unstructured sources.
-
Extract and normalize entities.
-
Link duplicate entities to canonical IDs.
-
Extract candidate relationships using rules, OpenIE, supervised models, distant supervision, LLMs, or a hybrid method.
-
Normalize raw predicates into a controlled relationship schema.
-
Add context such as dates, roles, locations, and source evidence.
-
Assign confidence and value scores.
-
Validate relationships with schema rules and quality checks.
-
Send high-risk or uncertain relationships to human review.
-
Store approved relationships in a graph database or RDF store.
-
Monitor freshness, conflicts, user feedback, and graph performance.
Final Thoughts¶
The value of a knowledge graph is not measured by the number of nodes and edges it contains. It is measured by the quality of the relationships it can use to answer meaningful questions.
High-value knowledge graph relationships are specific, trusted, contextual, and useful. They connect the right entities in the right way, with enough evidence for people and systems to rely on them. The best extraction pipelines combine human domain knowledge, clear schemas, strong source selection, automated extraction, provenance, validation, and continuous improvement.
A graph built this way becomes more than a database. It becomes a living map of knowledge that supports search, discovery, reasoning, analytics, automation, and better decisions.
References¶
-
W3C. “RDF 1.1 Concepts and Abstract Syntax.” Defines RDF triples and explains how predicates describe relationships between resources.
-
Hogan, A., Blomqvist, E., Cochez, M., et al. “Knowledge Graphs.” ACM Computing Surveys / arXiv. Provides a broad survey of knowledge graph data models, schema, identity, extraction, quality, refinement, and publication.
-
Noy, N., Gao, Y., Jain, A., et al. “Industry-scale Knowledge Graphs: Lessons and Challenges.” Google Research / Communications of the ACM. Discusses enterprise knowledge graph use cases across search, products, social networks, and AI systems.
-
Stanford CoreNLP. “OpenIE.” Documentation describing extraction of open-domain subject–relation–object triples.
-
W3C. “Shapes Constraint Language (SHACL).” Defines SHACL as a language for validating RDF graphs against shapes and constraints.
-
W3C. “PROV-O: The PROV Ontology.” Provides a standard ontology for representing and exchanging provenance information.
-
Schema.org. “Schema.org.” Describes a vocabulary for entities, relationships, and actions that can be expressed through RDFa, Microdata, and JSON-LD.
-
Google Search Central. “Introduction to Structured Data Markup in Google Search.” Explains how structured data helps Google understand page content and notes Google’s general recommendation to use JSON-LD when possible.
-
Neo4j Graph Data Science Documentation. “Centrality.” Describes centrality algorithms used to identify important nodes in graph networks.