Building Agentic RAG on Neo4j’s Knowledge Graph¶
Author: Yogender Pal
Published:
Source: https://pub.towardsai.net/building-agentic-rag-on-neo4js-knowledge-graph-fc9612d195e4
Fetched: 2026-06-07T02:46:12.473307
Building Agentic RAG on Neo4j’s Knowledge Graph¶
Vector embeddings retrieve “similar text.” Neo4j retrieves the truth. Here’s how Agentic RAG brings them together.¶
Press enter or click to view image in full size

Photo by Land O’Lakes, Inc. on Unsplash
Code is available in chapter5/rag.py:
You need some understanding of Neo4j and Langchain.
Introduction¶
RAG systems relying entirely on vector similarity search works beautifully — as long as your questions are fuzzy, conceptual, or descriptive. But the moment you need precise, structured, or multi-hop answers, semantic search collapses.
Ask a typical vector-based RAG system:
- Which contracts are active? (Aggregation)
- Who acted in The Matrix, and what other films were they in? (multi-hop).
- How many suppliers connected to Vendor X through Y (two hops).
- How many agreements expire next quarter? (Aggregation)
And it will give you something that sounds reasonable but is not guaranteed to be correct.
This article walks through:
- Why vector similarity alone fails in structured domains and for relational questions
- How graph reasoning fixes hallucinations at their root
- How to design tool descriptions that LLMs consistently choose
- How an Agentic RAG pipeline can decide when to use a graph query
- How I built LLM tool-calling that generates + executes Cypher
Process overview¶
The process begins with a question-normalization stage, where the input is rewritten into a deterministic, atomic form to eliminate ambiguity. This refined query is then passed to an LLM-based tool router, which selects the appropriate execution path — either a direct lookup tool or the Text2Cypher generator for complex, relationship-aware graph queries. The selected tool executes against Neo4j, returning structured results that are subsequently evaluated by an LLM critique module. This critique process identifies whether the returned data fully satisfies the original question and, if not, automatically generates additional targeted sub-queries that re-enter the routing and execution loop. Only when the system determines that all necessary information has been retrieved does it produce a final answer, ensuring responses remain strictly grounded in database results with no external fabrication.
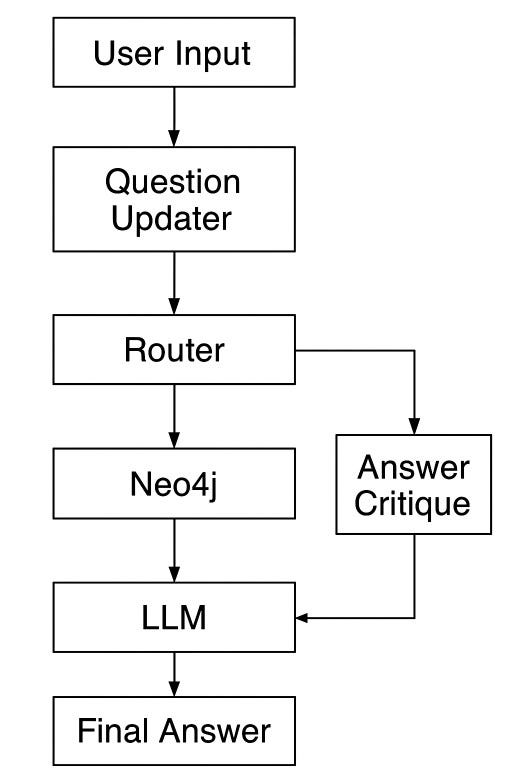
Info flow (image by llm)
1. Install Neo4j in Ubuntu machine:¶
# 1. download binaries
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo gpg --dearmor -o /etc/apt/keyrings/neotechnology.gpg
echo 'deb [signed-by=/etc/apt/keyrings/neotechnology.gpg] https://debian.neo4j.com stable latest' | sudo tee -a /etc/apt/sources.list.d/neo4j.list
sudo apt-get update
#2. install
sudo apt-get install neo4j=1:2025.10.1
sudo systemctl enable neo4j
#3. check status
sudo systemctl start neo4j
sudo systemctl status neo4j
# output
● neo4j.service - Neo4j Graph Database
Loaded: loaded (/usr/lib/systemd/system/neo4j.service; enabled; preset: en>
Active: active (running) since Sun 2025-12-07 05:57:10 CET; 24h ago
Main PID: 2360 (java)
Tasks: 132 (limit: 37947)
Memory: 1.0G (peak: 1.0G)
CPU: 26min 31.786s
CGroup: /system.slice/neo4j.service
├─2360 /usr/bin/java -Xmx128m -classpath "/usr/share/neo4j/lib/*:/>
└─3081 /usr/lib/jvm/java-21-openjdk-amd64/bin/java -cp "/var/lib/n>
#4. set default server on localhost: uncomment server.default_listen_address=0.0.0.0 in neo4j.config
sudo nano /etc/neo4j/neo4j.conf
server.default_listen_address=0.0.0.0
#5 run in web browser:
http://127.0.0.1:7474
# username: neo4j, password: neo4j, you would need to change the password once logged in
2. Download Movie graph in Neo4j¶
Press enter or click to view image in full size
Downloading movie graph in the Neo4j local instance
Visualizing the graph
# run in the bar too see all the nodes and relationships:
MATCH (n)-[r]->(m)
RETURN n, r, m
#or to see nodes:
MATCH (m:Movie)
RETURN m;
Press enter or click to view image in full size
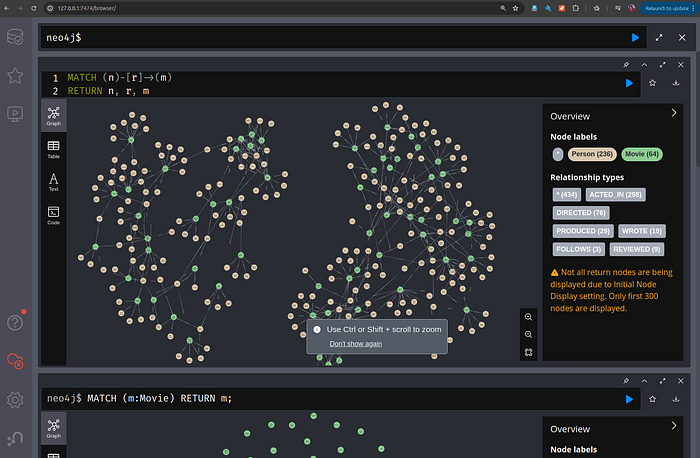
movies graph visualization
It has two types of nodes (lables): Person and Movies. The relationship types from Person -> Movies is also shown as ACTED_IN, DIRECTED, PRODUCED and so on.
3. Agentic Graph RAG on Neo4j’s Knowledge Graph¶
Schema Extracter
Primary purpose of this code is to interrogate a live Neo4j database, extract its nodes, relationships, and properties, and convert that into a textual schema representation that an LLM can use to generate accurate Cypher queries. Why we need to LLM to generate Cypher queries? Because LLMs are good a it and we want to use natural language to generate Cypher queries which in turn will be used to extract the data from the graph.
The script starts by establishing a connection to Neo4j using the official Python driver. APOC’s apoc.meta.data() procedure is a tool that reveals the entire structure of a Neo4j graph—node labels, relationship types, directions, and property definitions (you need to install it). The first query extracts all node labels and groups their associated properties. The second does the same for relationship types, including any relationship-level attributes. Finally, the third query maps out the directional graph structure: which node labels are connected, through which relationships, and in what direction. if you run these query in cypher-shell you can see the schema of the movie graph.
Press enter or click to view image in full size
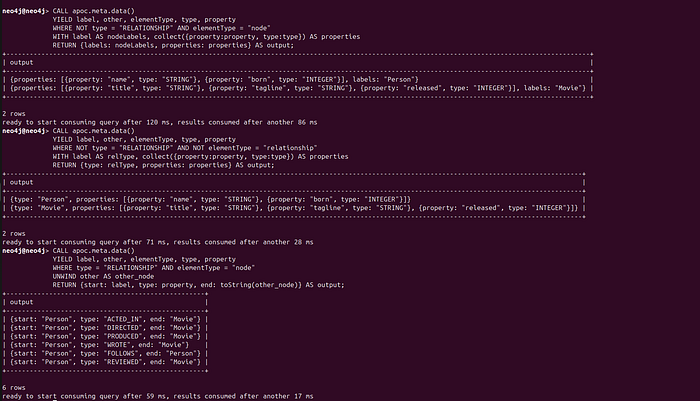
Schema Extracter in cypher-shell
import re
from typing import List
import pdfplumber
import requests
imporpyt tiktoken
from neo4j import GraphDatabase
from typing import Any
import neo4j
from typing import Literal
from langchain_google_vertexai import ChatVertexAI
import json
import re
driver = GraphDatabase.driver("neo4j://127.0.0.1:7687",
auth=("neo4j", "qawsedRF123"),
notifications_min_severity="OFF"
)
NODE_PROPERTIES_QUERY = """
CALL apoc.meta.data()
YIELD label, other, elementType, type, property
WHERE NOT type = "RELATIONSHIP" AND elementType = "node"
WITH label AS nodeLabels, collect({property:property, type:type}) AS properties
RETURN {labels: nodeLabels, properties: properties} AS output
"""
REL_PROPERTIES_QUERY = """
CALL apoc.meta.data()
YIELD label, other, elementType, type, property
WHERE NOT type = "RELATIONSHIP" AND NOT elementType = "relationship"
WITH label AS relType, collect({property:property, type:type}) AS properties
RETURN {type: relType, properties: properties} AS output
"""
REL_QUERY = """
CALL apoc.meta.data()
YIELD label, other, elementType, type, property
WHERE type = "RELATIONSHIP" AND elementType = "node"
UNWIND other AS other_node
RETURN {start: label, type: property, end: toString(other_node)} AS output
"""
def get_structured_schema(driver: neo4j.Driver) -> dict[str, Any]:
node_labels_response = driver.execute_query(NODE_PROPERTIES_QUERY)
node_properties = [
data["output"] for data in [r.data() for r in node_labels_response.records]
]
rel_properties_query_response = driver.execute_query(REL_PROPERTIES_QUERY)
rel_properties = [
data["output"]
for data in [r.data() for r in rel_properties_query_response.records]
]
rel_query_response = driver.execute_query(REL_QUERY)
relationships = [
data["output"] for data in [r.data() for r in rel_query_response.records]
]
return {
"node_props": {el["labels"]: el["properties"] for el in node_properties},
"rel_props": {el["type"]: el["properties"] for el in rel_properties},
"relationships": relationships,
}
def get_schema(
driver: neo4j.Driver,
) -> str:
structured_schema = get_structured_schema(driver)
def _format_props(props: list[dict[str, Any]]) -> str:
return ", ".join([f"{prop['property']}: {prop['type']}" for prop in props])
formatted_node_props = [
f"{label} {{{_format_props(props)}}}"
for label, props in structured_schema["node_props"].items()
]
formatted_rel_props = [
f"{rel_type} {{{_format_props(props)}}}"
for rel_type, props in structured_schema["rel_props"].items()
]
formatted_rels = [
f"(:{element['start']})-[:{element['type']}]->(:{element['end']})"
for element in structured_schema["relationships"]
]
return "\n".join(
[
"Node properties:",
"\n".join(formatted_node_props),
"Relationship properties:",
"\n".join(formatted_rel_props),
"The relationships:",
"\n".join(formatted_rels),
]
)
Once the metadata is returned, the get_structured_schema() function transforms it into a consistent Python dictionary. It assembles a mapping of node labels to property lists, relationship types to their own properties, and a list describing all (start node)–(relationship)–(end node) tuples. This structured representation is extremely valuable for any downstream AI agent because it provides the precise context needed to decide which nodes to traverse and how to construct valid Cypher queries. Without this schema, an LLM would be effectively guessing, which often leads to broken queries or hallucinated property names.
The final step is converting the schema object into a clean, readable text block through the get_schema() function. This is where the data becomes LLM-friendly. The function formats each node’s properties into lines like Movie {title: STRING, released: INTEGER}, relationship properties into their own section, and the graph’s structural relationships into canonical Cypher patterns like (:Person)-[:ACTED_IN]->(:Movie). This compact, human-readable representation can be directly injected into an LLM prompt, enabling the model to understand the graph exactly as Neo4j defines it. When the agent sees this schema, it can confidently infer the correct nodes, properties, and paths to use when answering natural-language questions.
Text2Cypher¶
prompt_template = {
"static": {
"instructions": """
Instructions:
Generate Cypher statement to query a graph database to get the data to answer the user question below.
Format instructions:
Do not include any explanations or apologies in your responses.
Do not respond to any questions that might ask anything else than for you to
construct a Cypher statement.
Do not include any text except the generated Cypher statement.
ONLY RESPOND WITH CYPHER, NO CODEBLOCKS.
Make sure to name RETURN variables as requested in the user question.
"""
},
"dynamic": {
"schema": """
Graph Database Schema:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided in the schema.
{}
""",
"terminology": """
Terminology mapping:
This section is helpful to map terminology between the user question and the graph database schema.
{}
""",
"examples": """
Examples:
The following examples provide useful patterns for querying the graph database.
{}
""",
"question": """
User question: {}
""",
},
}
class Text2Cypher:
def __init__(self, driver: neo4j.Driver):
self.driver = driver
self.dynamic_sections = {}
self.required_sections = ["question"]
self.prompt_template = prompt_template
schema_string = get_schema(driver)
self.set_prompt_section("schema", schema_string)
def set_prompt_section(
self,
section: Literal["terminology", "examples", "schema", "question"],
value: str,
):
self.dynamic_sections[section] = value
def get_full_prompt(self):
prompt = self.prompt_template["static"]["instructions"]
print ('prompt=======', prompt)
# loop through the prompt_template["dynamic"] and add the values from self.dynamic_sections
for section in self.prompt_template["dynamic"]:
if section in self.dynamic_sections:
prompt += self.prompt_template["dynamic"][section].format(
self.dynamic_sections[section]
)
return prompt
def generate_cypher(self):
# check if required sections are set
for section in self.required_sections:
if section not in self.dynamic_sections:
raise ValueError(
f"Section {section} is required to generate a prompt. Use set_prompt_section to set it."
)
prompt = self.get_full_prompt()
cypher = chat(messages=[{"role": "user", "content": prompt}])
return strip_code_cypher(cypher)
def chat(messages, **config):
llm = ChatVertexAI(model="gemini-2.0-flash")
return llm.invoke(messages, **config).content
The Text2Cypher class is responsible for turning a user’s natural-language question into a clean, executable Cypher query grounded in the actual Neo4j graph schema. When the class is initialized, it fetches the live database schema using get_schema() and stores it as one dynamic section of a larger prompt. These dynamic sections—such as schema, examples, terminology, and the user’s question—are combined with a static instruction block defined in a prompt_template. This allows the system to build a full prompt on the fly, ensuring the LLM always receives accurate context about the graph’s structure, node properties, relationship types, and expected query format.
When a query is requested, the class checks that all required sections (especially the question) are present, assembles the final prompt with get_full_prompt(), and sends it to the LLM via chat(). Because models often wrap their output in Markdown fences, the returned text is passed through strip_code_cypher() so only the Cypher remains. The result is a deterministic, schema-aligned query you can run directly against Neo4j. This mechanism makes the LLM far more reliable than vector search alone for tasks requiring exact graph traversal, property filtering, and structured aggregation—capabilities that embeddings cannot provide with the same precision.
Tools defination and description¶
answer_given_description = {
"type": "function",
"function": {
"name": "respond",
"description": "If the conversation already contains a complete answer to the question, use this tool to extract it. Additionally, if the user engages in small talk, use this tool to remind them that you can only answer questions about movies and their cast.",
"parameters": {
"type": "object",
"properties": {
"answer": {
"type": "string",
"description": "Respond directly with the answer",
}
},
"required": ["answer"],
},
},
}
def answer_given(answer: str):
"""Extract the answer from a given text."""
return answer
text2cypher_description = {
"type": "function",
"function": {
"name": "text2cypher",
"description": "Query the database with a user question. When other tools don't fit, fallback to use this one.",
"parameters": {
"type": "object",
"properties": {
"question": {
"type": "string",
"description": "The user question to find the answer for",
}
},
"required": ["question"],
},
},
}
def text2cypher(question: str):
"""Query the database with a user question."""
t2c = Text2Cypher(driver)
t2c.set_prompt_section("question", question)
cypher = t2c.generate_cypher()
try:
records, _, _ = driver.execute_query(cypher)
print ('neo4j data:', [record.data() for record in records])
return [record.data() for record in records]
except Exception as e:
return [f"{cypher} cause an error: {e}"]
movie_info_by_title_description = {
"type": "function",
"function": {
"name": "movie_info_by_title",
"description": "Get information about a movie by providing the title",
"parameters": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "The movie title",
}
},
"required": ["title"],
},
},
}
def movie_info_by_title(title: str):
"""Return movie information by title."""
query = """
MATCH (m:Movie)
WHERE toLower(m.title) CONTAINS $title
OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Person)
OPTIONAL MATCH (m)<-[:DIRECTED]-(d:Person)
RETURN m AS movie, collect(a.name) AS cast, collect(d.name) AS directors
"""
records, _, _ = driver.execute_query(query, title=title.lower())
return [record.data() for record in records]
movies_info_by_actor_description = {
"type": "function",
"function": {
"name": "movies_info_by_actor",
"description": "Get information about a movie by providing an actor",
"parameters": {
"type": "object",
"properties": {
"actor": {
"type": "string",
"description": "The actor name",
}
},
"required": ["actor"],
},
},
}
def movies_info_by_actor(actor: str):
"""Return movie information by actor."""
query = """
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Person)
OPTIONAL MATCH (m)<-[:DIRECTED]-(d:Person)
WHERE toLower(a.name) CONTAINS $actor
RETURN m AS movie, collect(a.name) AS cast, collect(d.name) AS directors
"""
records, _, _ = driver.execute_query(query, actor=actor.lower())
return [record.data() for record in records]
tools = {
"movie_info_by_title": {
"description": movie_info_by_title_description,
"function": movie_info_by_title
},
"movies_info_by_actor": {
"description": movies_info_by_actor_description,
"function": movies_info_by_actor
},
"text2cypher": {
"description": text2cypher_description,
"function": text2cypher
},
"answer_given": {
"description": answer_given_description,
"function": answer_given
}
}
This section defines the tooling layer that agent uses to decide how to answer a question. Each tool is described using function-calling schema, where you specify the tool name, its purpose, and the exact parameters it accepts. These descriptions are passed to the LLM so it can intelligently route the user’s query to the right function. For example, movie_info_by_title and movies_info_by_actor provide narrow, deterministic lookups using well-defined Cypher queries optimized for specific tasks like retrieving cast lists or fetching all movies tied to an actor. The answer_given tool is more meta—it allows the agent to short-circuit unnecessary processing if answer is present in the query itself. Meanwhile, text2cypher acts as a general fallback when no specialized tool fits; it delegates to your Text2Cypher class to dynamically generate Cypher directly from natural language.
Each tool is implemented as a Python function that executes real Neo4j queries through the shared database driver. The more specialized tools (movie_info_by_title and movies_info_by_actor) use parameterized Cypher to avoid hallucinations and deliver structured results. The text2cypher function is particularly powerful: it generates a Cypher query via LLM, sanitizes it, and executes it—but only after grounding the model in the live database schema. This gives your agent the flexibility of natural-language interaction with the safety of schema-aligned execution. All tools are finally collected in the tools dictionary so the router can look them up by name, ensuring your agent can seamlessly switch between deterministic graph lookups and LLM-assisted generation depending on the user’s needs.
Tool Routers
tool_picker_prompt = """
Your job is to chose the right tool needed to respond to the user question.
The available tools are provided to you in the prompt.
Make sure to pass the right and the complete arguments to the chosen tool.
"""
def handle_tool_calls(tools: dict[str, any], llm_tool_calls: list[dict[str, any]]):
output = []
if llm_tool_calls:
print ('llm_tool_calls:', llm_tool_calls)
for tool_call in llm_tool_calls:
function_to_call = tools[tool_call['name']]["function"]
print ('function_to_call:', function_to_call)
function_args = tool_call.get("args", {})
print('function arguments:', function_args)
res = function_to_call(**function_args)
print ('res function to call:', res)
output.append(res)
return output
def tool_choice(messages,temperature=0, tools=[], config={}, model=None):
llm = ChatVertexAI(model="gemini-2.0-flash")
return llm.invoke(messages, tools=tools).tool_calls
def route_question(question: str, tools: dict[str, any], answers: list[dict[str, str]]):
llm_tool_calls = tool_choice(
[
{
"role": "system",
"content": tool_picker_prompt,
},
*answers,
{
"role": "user",
"content": f"The user question to find a tool to answer: '{question}'",
},
],
tools=[tool["description"] for tool in tools.values()],
)
return handle_tool_calls(tools, llm_tool_calls)
The tool_choice() function then hands the conversation—along with the tool definitions—to Vertex AI’s Gemini model, which returns a list of tool calls. From there, handle_tool_calls() becomes the execution engine: it resolves each tool name to an actual Python function, extracts the arguments proposed by the LLM, and executes the corresponding function. The route_question() helper ties everything together by packaging the conversation history, the user question, and the available tool specifications into a single prompt—letting the LLM “think” about which tool provides the most accurate, context-aware response.
Query updater agent
query_update_prompt = """
You are an expert at updating questions to make the them ask for one thing only, more atomic, specific and easier to find the answer for.
You do this by filling in missing information in the question, with the extra information provided to you in previous answers.
You respond with the updated question that has all information in it.
Only edit the question if needed. If the original question already is atomic, specific and easy to answer, you keep the original.
Do not ask for more information than the original question. Only rephrase the question to make it more complete.
JSON template to use:
{
"question": "question1"
}
DO NOT ADD ```json ``` and whitespaces in your response.
"""
def query_update(input: str, answers: list[any]) -> str:
messages = [
{"role": "system", "content": query_update_prompt},
*answers,
{"role": "user", "content": f"The user question to rewrite: '{input}'"},
]
config = {"response_format": {"type": "json_object"}}
output = chat(messages, response_format={"type": "json_object"})
jsonloads = json.loads(strip_code_fences(output))
print ('1:', jsonloads)
try:
return jsonloads["question"]
except json.JSONDecodeError:
print("Error decoding JSON 1")
return []
def handle_user_input(input: str, answers: list[dict[str, str]] = []):
updated_question = query_update(input, answers)
response = route_question(updated_question, tools, answers)
answers.append({"role": "assistant", "content": f"For the question: '{updated_question}', we have the answer: '{json.dumps(response)}'"})
return answers
query_update uses an LLM to rewrite a user’s question into a more precise, atomic version by leveraging prior answers for missing context; it enforces a strict JSON format, parses the cleaned output, and returns the improved question. The handle_user_input function then orchestrates the workflow by taking the user’s raw query, converting it into this refined version, routing it through the tool-selection logic, storing the resulting answer in the conversation history, and returning the updated state—ensuring each user message becomes clearer, more actionable, and easier for downstream tools to handle.
Critic agent¶
answer_critique_prompt = """
You are an expert at identifying if questions has been fully answered or if there is an opportunity to enrich the answer.
The user will provide a question, and you will scan through the provided information to see if the question is answered.
If anything is missing from the answer, you will provide a set of new questions that can be asked to gather the missing information.
All new questions must be complete, atomic and specific.
However, if the provided information is enough to answer the original question, you will respond with an empty list.
JSON template to use for finding missing information:
{
"questions": ["question1", "question2"]
}
"""
def critique_answers(question: str, answers: list[dict[str, str]]) -> list[str]:
messages = [
{
"role": "system",
"content": answer_critique_prompt,
},
*answers,
{
"role": "user",
"content": f"The original user question to answer: {question}",
},
]
config = {"response_format": {"type": "json_object"}}
output = chat(messages=messages, response_format={"type": "json_object"})
jsonloads = json.loads(strip_code_fences(output))
print ('2:', jsonloads)
try:
return jsonloads["questions"]
except json.JSONDecodeError:
print("Error decoding JSON 2")
return []
This module adds an automated quality-check step that evaluates whether a user’s question has been fully answered. The answer_critique_prompt instructs the LLM to review the original question and all previous answers, then decide whether the response is complete. If anything is missing, the model must generate a list of precise, atomic follow-up questions; otherwise, it returns an empty list. The critique_answers function builds the message stack, calls the LLM with a strict JSON format, sanitizes the output with strip_code_fences, and parses the resulting list. This creates a clean, deterministic signal for whether more information is needed or the answer is already sufficient.
Main agent¶
main_prompt = """
Your job is to help the user with their questions.
You will receive user questions and information needed to answer the questions
If the information is missing to answer part of or the whole question, you will say that the information
is missing. You will only use the information provided to you in the prompt to answer the questions.
You are not allowed to make anything up or use external information.
"""
def main(input: str):
answers = handle_user_input(input)
critique = critique_answers(input, answers)
if critique:
answers = handle_user_input(" ".join(critique), answers)
llm_response = chat(
[
{"role": "system", "content": main_prompt},
*answers,
{"role": "user", "content": f"The user question to answer: {input}"},
]
)
return llm_response
response = main("Who's the main actor in the movie Matrix and what other movies is that person in?")
response
Out[5]: 'Based on the information provided, the main actors in "The Matrix" are Emil Eifrem, Hugo Weaving, Laurence Fishburne, Carrie-Anne Moss, and Keanu Reeves.\n\nHere are other movies they have starred in:\n* **Emil Eifrem:** The Matrix\n* **Hugo Weaving:** Cloud Atlas, V for Vendetta, The Matrix Revolutions, The Matrix Reloaded, The Matrix,\n* **Laurence Fishburne:** The Matrix Revolutions, The Matrix Reloaded, The Matrix\n* **Carrie-Anne Moss:** The Matrix Revolutions, The Matrix Reloaded, The Matrix\n* **Keanu Reeves:** Something\'s Gotta Give, The Replacements, Johnny Mnemonic, The Devil\'s Advocate, The Matrix Revolutions, The Matrix Reloaded, The Matrix'
This final layer acts as the orchestrator that ties the entire agentic workflow together. The main_prompt constrains the model to rely strictly on provided information—never external knowledge—ensuring answers remain grounded in Neo4j-queried data and prior tool outputs. The main function coordinates the process: it first routes the user query through the tool pipeline, collects the initial answers, and then invokes the critique module to check for missing information. If gaps are detected, it automatically triggers a second tool pass using the follow-up questions. Finally, it compiles all accumulated answers and feeds them—along with the original question—into a clean, deterministic LLM call. The function returns a final response that is complete, context-aware, and strictly derived from the structured graph data and agent workflow.
That is all!