Why LLMs Fail at Knowledge Graph Extraction (And What Works Instead)¶
Author: Fabio Yáñez Romero
Published:
Source: https://pub.towardsai.net/why-llms-fail-at-knowledge-graph-extraction-and-what-works-instead-dcb029f35f5b
Fetched: 2026-06-07T02:52:34.141615
Why LLMs Fail at Knowledge Graph Extraction (And What Works Instead)¶
From Entity Extraction to Graph Augmentation: What Every ML Engineer Needs to Know¶
When an AI system confidently extracts ‘Party A,’ ‘the plaintiff,’ and ‘the aforementioned party’ as three separate entities from a single legal paragraph — all referring to the same organisation — the knowledge graph becomes unusable.
Despite GPT-5’s impressive capabilities in text generation and reasoning, building reliable knowledge graphs from unstructured text remains a fundamental challenge — one that reveals critical gaps between how language models work and what structured knowledge extraction requires.
During my PhD research on extracting knowledge graphs from legal documents, I discovered that successful KG generation isn’t just about avoiding hallucinations.
It requires understanding the architectural tradeoffs between model types, defining what ground truth means for your domain, and knowing when extracted graphs need augmentation for downstream tasks.
Press enter or click to view image in full size
An artificial intelligence model, thinking about the knowledge graph it will provide as answer (and the many flaws it will contain). Image generated with nano banana pro.
This matters particularly for Retrieval Augmented Generation (RAG) systems and knowledge base population, where structural integrity and semantic consistency are non-negotiable. As GraphRAG and similar architectures enter production environments, practitioners need to understand these foundational concepts before choosing extraction approaches.
In this post, I’ll explain the core challenges in automated knowledge graph generation — why generative models struggle with structured extraction, how discriminative alternatives compare, and what defines a high-quality knowledge graph for production systems.
This foundation will prepare you for the follow-up post, where I’ll demonstrate how Google’s LangExtract addresses these challenges with a hands-on implementation for paragraph-level extraction.
📌 Key Takeaways¶
- Understand why LLMs struggle with structured KG extraction
- Learn the difference between asserted and augmented knowledge graphs
- Discover when to use discriminative vs. generative models
- Explore 5 augmentation strategies with practical tradeoffs
Why Language Models Struggle with Knowledge Graph Extraction¶
Let’s start by examining why even state-of-the-art models struggle with structured extraction. The challenge extends far beyond hallucinations — it involves fundamental mismatches between how language models generate text and the requirements of knowledge graphs.
Generative models face several interconnected problems when building knowledge graphs:
- Entity disambiguation: The same entity appears multiple times with different phrasings, and naive extraction misses coreferences, fragmenting the graph
- Compositional entities: Terms like “City of Mexico” refer to nested concepts (both city and country), requiring hierarchical representation
- Hallucination at scale: Probabilistic generation produces plausible but false entities and relationships, especially with larger texts that need to be processed in sequence.
- Context-dependent relationships: Many entity connections only make sense with full document context, but processing entire documents amplifies hallucination rates.
In my legal document analysis, I observed this firsthand: even within a single paragraph, the model would identify “Party A” as a single entity and then treat subsequent references, such as “the aforementioned party,” as separate entities — despite all of them referring to the same organisation.
This fragmentation within individual paragraphs made the resulting graphs noisy and required extensive post-processing to correctly represent the ground truth.
Some practitioners process text in smaller chunks to reduce hallucinations, but this creates relationship loss and entity duplication. Even at the paragraph level, important entity connections can span multiple sentences, and aggressive chunking to the sentence level destroys these dependencies entirely. Moreover, it becomes more costly as the model must run multiple inference passes to process the same content.
The context loss is a problem that increases with smaller contexts — it’s problematic at paragraph level and even worse at sentence level
These limitations in generative architectures raise an important question: are there alternative model types better suited for structured extraction?
Discriminative vs. Generative Models for Knowledge Graph Extraction¶
Discriminative language models — those with bidirectional attention trained on masked language modelling — offer a compelling alternative for knowledge graph extraction.
Why this advantage? Discriminative models excel at token and sequence classification. Named entity recognition can be framed as token-level classification over the input sequence, eliminating the generation step entirely.
Detecting named entities can be handled as a token classification, eliminating the generation process
This architectural fit makes them not only more accurate for structured extraction but also efficient enough for edge deployment — a BERT-based model can run on modest hardware while GPT-5 requires substantial compute resources.
The tradeoff is flexibility:
- Discriminative models require task-specific fine-tuning on domain data, but achieve better performance than naïve approaches using generative language models.
- Generative models, by contrast, can be adapted through in-context learning with prompts and few-shot examples, requiring no additional training.
For legal document analysis, this means choosing between a fine-tuned discriminator (higher accuracy, domain-locked) and a prompted generative model (lower accuracy, highly adaptable).
This efficiency-versus-flexibility tradeoff shapes a fundamental question: what kind of knowledge graph are we actually trying to build?
Regardless of model choice, successful extraction requires starting with a solid foundation — what researchers call an asserted knowledge graph that represents ground truth from the source text. This foundation becomes critical when iterative refinement is needed.
Asserted Knowledge Graphs: Your Verifiable Foundation¶
An asserted knowledge graph represents only the explicit information stated in the source text — no inference, no external knowledge, just what’s directly present. In our case, the source is the text itself, making this graph the verifiable ground truth for that document.
Creating an asserted knowledge graph requires three core tasks:
- Entity Recognition: Identifying and classifying key spans like persons, organisations, dates, or domain-specific terms.
- Relation Extraction: Finding explicit connections between entities.
- Coreference Resolution: Linking different mentions of the same entity to a single node.
These tasks align naturally with the strengths of discriminative models in token and sequence classification — which is why specialised BERT-based systems often tackle them separately.
However, this intuitive pipeline approach introduces a critical problem.
The Pipeline Problem: How Accuracy Drops Dramatically¶
These tasks are typically performed sequentially: extract entities, then detect relations, then resolve coreferences. However, this multi-stage pipeline accumulates errors at each step.
A 90% accurate entity recognizer feeding into a 90% accurate relation extractor yields only 81% overall accuracy — and that’s before coreference resolution introduces additional errors…
Error propagation explains why modern approaches favour end-to-end models that generate the graph in one step
A single language model generating the complete graph structure in one pass avoids the compounding failures of chained specialised models, even if each specialised component performs better on its isolated subtask.
Why Asserted Graphs Are Non-Negotiable for Production¶
The asserted knowledge graph serves as your verifiable baseline. When downstream tasks require additional information — implicit relationships, connections to external knowledge bases, or domain-specific augmentation — you can expand from this trusted foundation rather than questioning the entire graph’s validity.
This becomes critical for production systems, where explainability and debugging depend on knowing which information came directly from the source rather than from inference or augmentation.
However, this verifiable foundation alone may not be sufficient for many real-world applications, which is where augmentation strategies become necessary.
Augmenting the Asserted Knowledge Graph¶
The asserted knowledge graph, on its own, is often insufficient for real-world applications. After extracting ground truth from legal documents , I consistently encountered three fundamental limitations:
- Disconnected components: Many graphs contain isolated entity clusters with no connecting paths, limiting traversability
- Missing implicit knowledge: Real documents assume a shared context that isn’t explicitly stated.
- External alignment needs: Entities require normalisation to broader knowledge bases for downstream integration.
These gaps necessitate strategic augmentation approaches.
Press enter or click to view image in full size
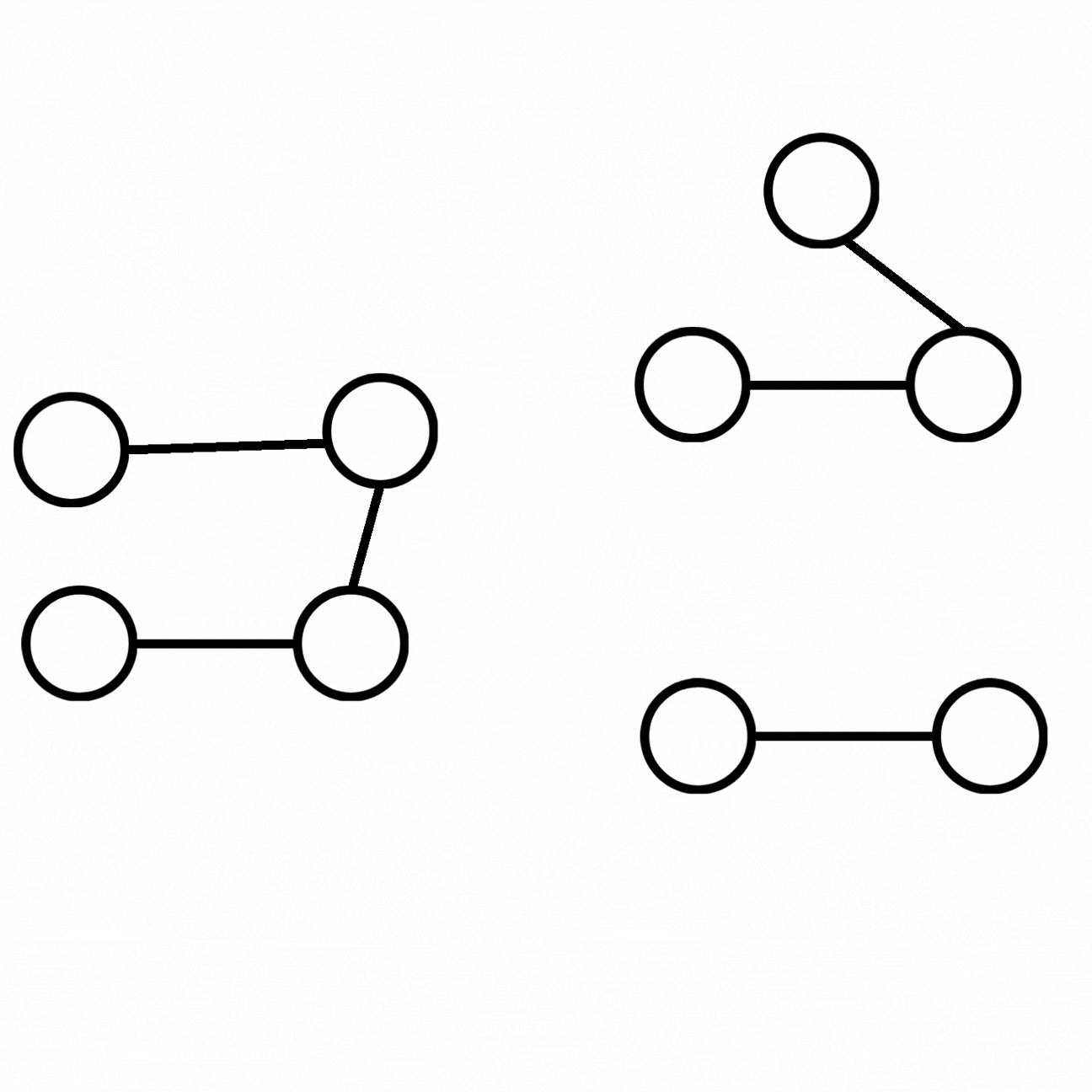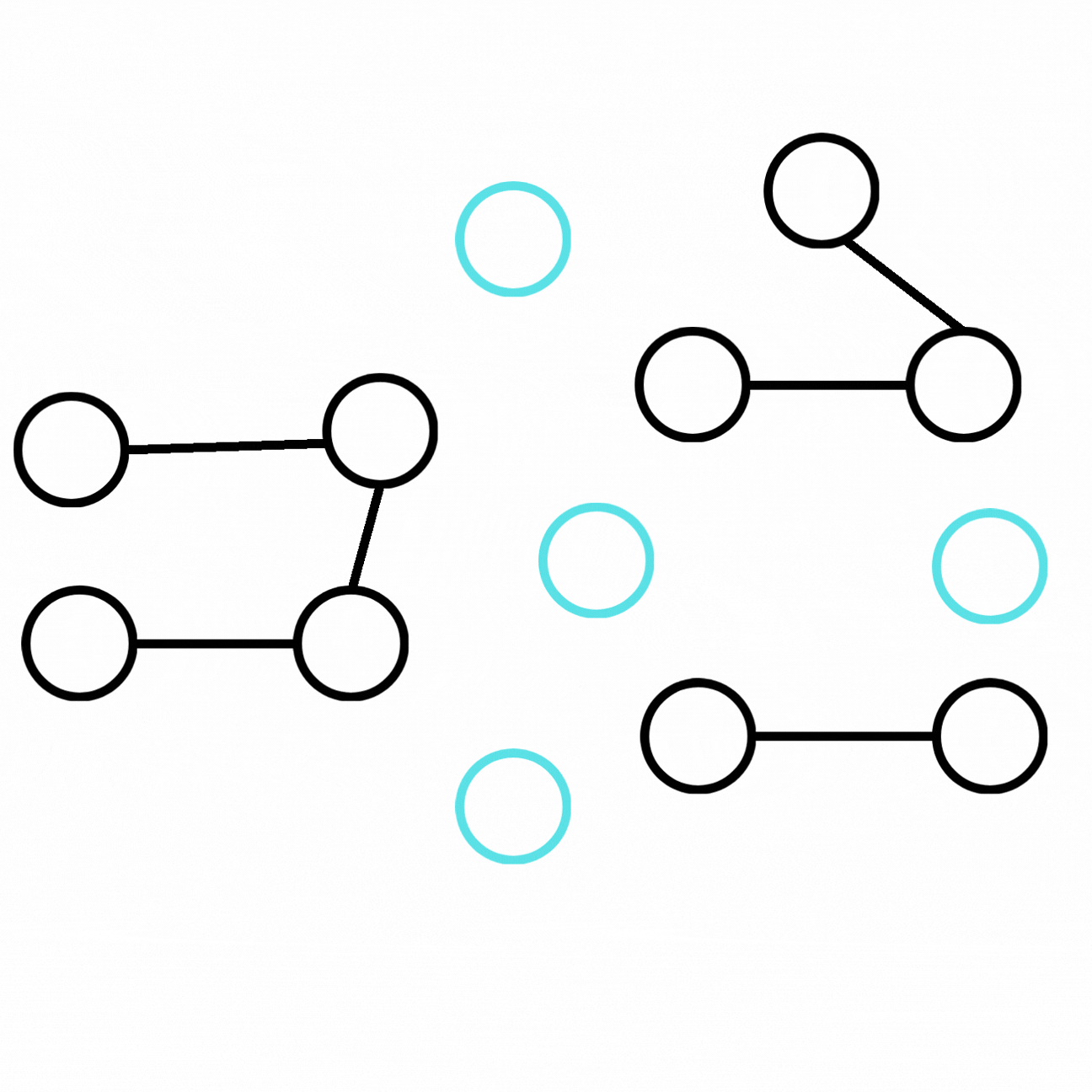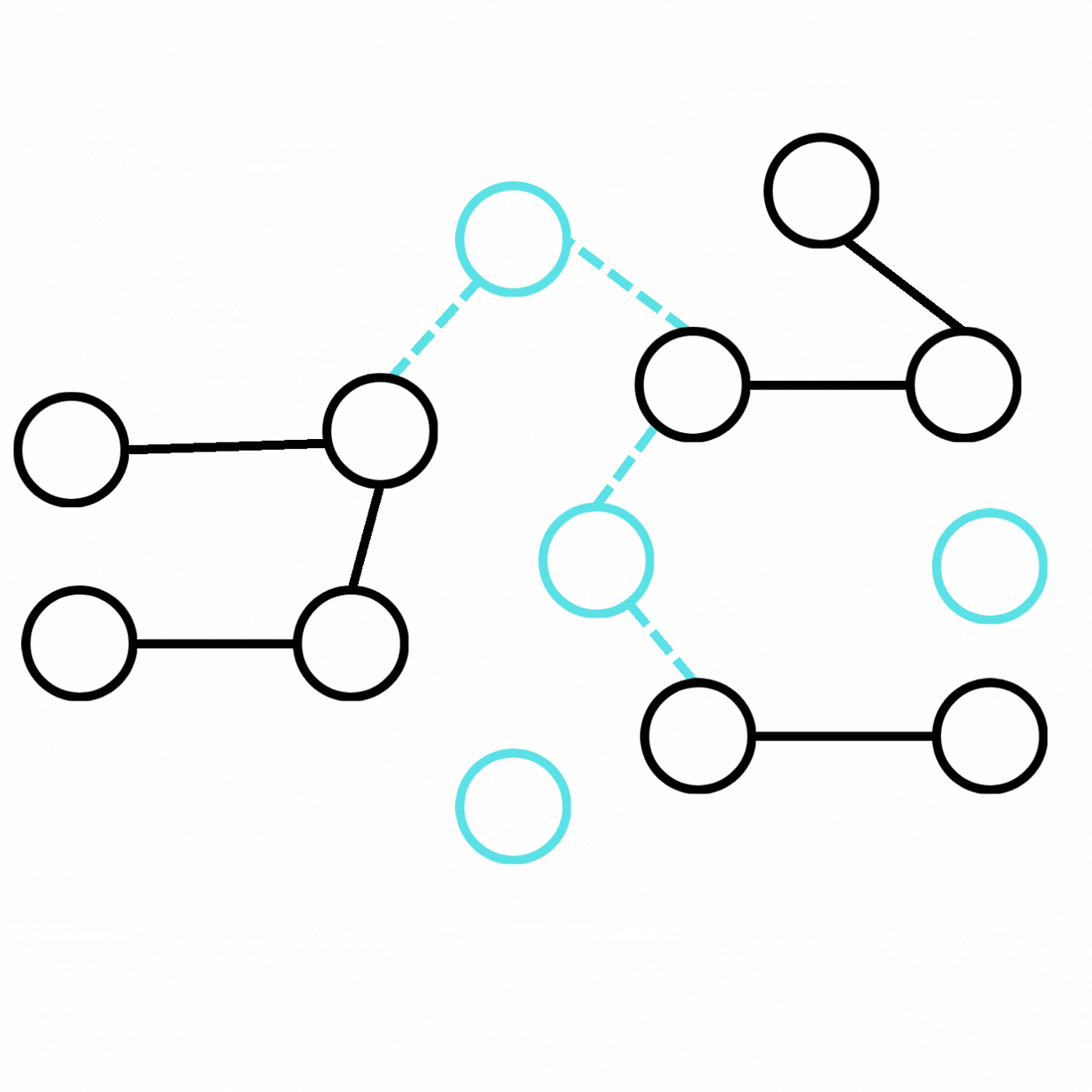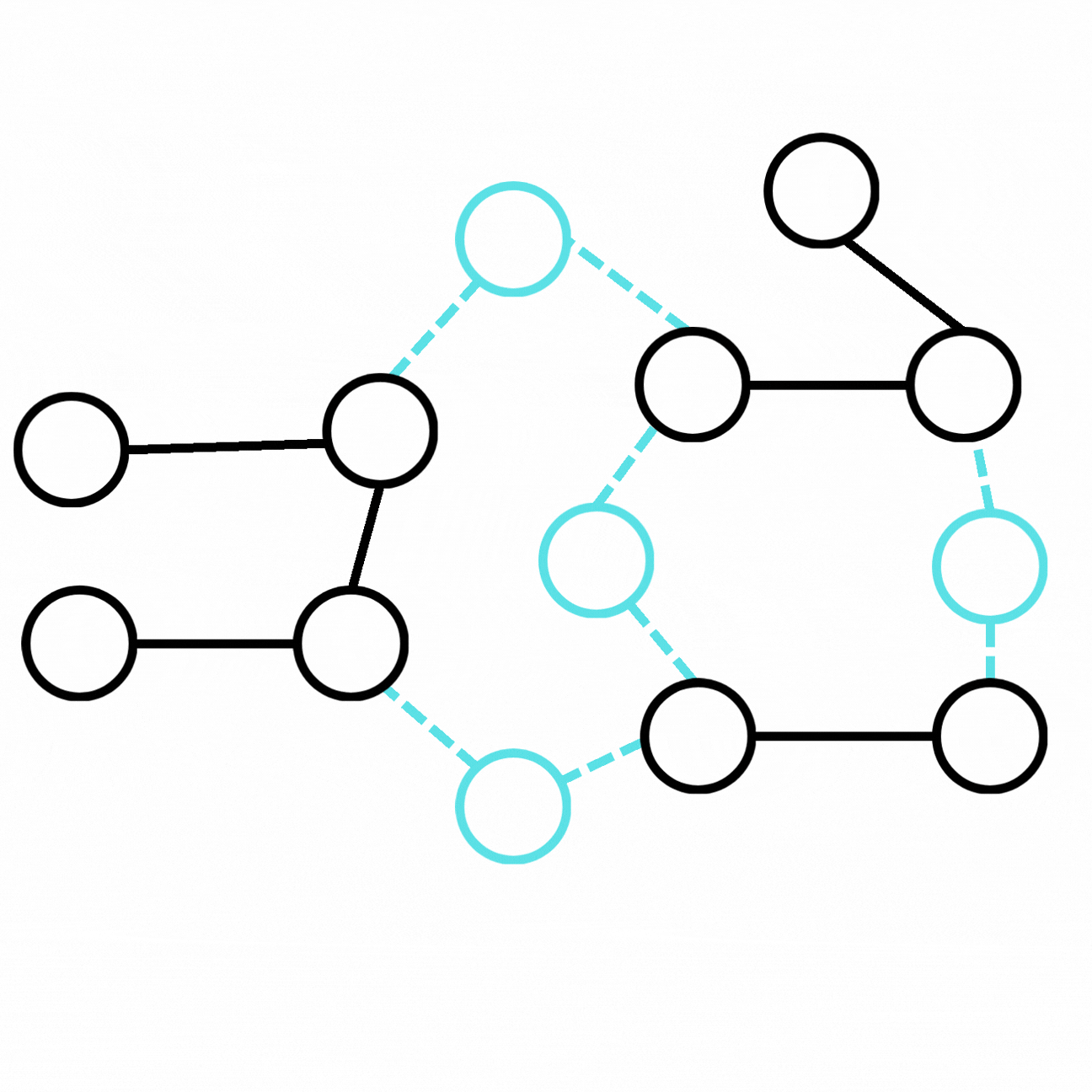
We can obtain an augmented graph from the ground-truth graph by adding new entities and relations connected to our initial graph.
Taxonomic Augmentation: Building Knowledge Hierarchies¶
The downstream task might benefit from intuitive relations that are easy to automatically generate (“is a,” “located in,” “part of”, etc). For legal documents, this includes inferring standard roles like “judge,” “plaintiff,” or “legal case” from contextual clues.
Hierarchical relationships prove particularly valuable — adding taxonomic connections that organise entities into ontological structures. For instance, establishing that [employment contract, is a, legal contract] or [Party A, is a corporation] creates navigable hierarchies from flat lists of entities.
Generative language models can handle this augmentation when constrained to predefined relation vocabularies — unconstrained generation risks hallucinations and might collapse into standard hierarchical relationships more typical of common knowledge than of specific domains.
Rule-Based Augmentation¶
Another approach leverages logical rules to infer new facts from existing patterns. Simple rules like “if Entity A employs Entity B, then Entity A is an organisation” codify domain knowledge explicitly.
Multi-hop rules enable more complex inference: “if case A violates article 5, and article 5 belongs to regulation R, then case A also violates regulation R.” These chained inferences can dramatically increase graph connectivity and reveal implicit relationships.
Press enter or click to view image in full size

Example of a Domain specific rule for augmenting the relations in the asserted graph.
The tradeoff is that rule-based augmentation requires expert knowledge to define valid inference patterns.
Unlike learned approaches, rules won’t generalise beyond what domain experts explicitly encode — but they also won’t hallucinate invalid relationships, making them reliable when correctness is paramount.
Link Prediction with Knowledge Base Alignment¶
One approach is identifying missing relations within the existing entity set, thereby increasing graph connectivity without adding new nodes. This can be accomplished by training models on link prediction over domain-specific knowledge bases.
The model trains on triples [Entity A — Relation — Entity B] and learns to infer whether a relation exists between any two entities, and if so, what type.
Alternatively, generative language models can predict missing relations through prompting, though this approach is more prone to hallucinations and requires carefully defining valid relation subsets.
Press enter or click to view image in full size

Training and inference process of an entity linking model. The models trained this way tend to use diverse geometric spaces encoded in their loss functions to capture complex relations among entities, or through language models.
Source Context Preservation¶
Another approach augments the graph by preserving the original source structure.
This involves creating nodes that represent text spans — sentences, paragraphs, or entire documents — and implementing them in two ways: either connecting these nodes to their related entities (increasing overall graph connectivity) or creating a nested hierarchy in which higher-level text nodes contain the subgraphs extracted from their content.
This augmentation adds valuable context without introducing factual errors, since you’re representing what actually exists in the source rather than inferring new knowledge.
When an entity appears in multiple contexts, these provenance nodes reveal usage patterns and semantic relationships that weren’t explicitly stated in individual entity connections.
This way, you can trace any entity or relationship back to its exact source location, understanding not just what was extracted but where it came from and in what context it appeared.
Note that simpler implementations can achieve similar traceability by storing source metadata (document IDs, sentence positions) directly on entity and relation nodes during graph construction, thereby avoiding the overhead of additional structural nodes.
The choice between metadata and explicit nodes depends on whether your downstream task benefits from treating text spans as queryable graph entities themselves.
Topic Clustering for Connectivity¶
Disconnected components remain problematic for graph traversal and global queries. Topic-based clustering addresses this by creating bridge nodes that connect related entities.
A straightforward approach uses predefined categories: train a classification model on domain-specific topics (e.g., for legal documents: “employment law,” “intellectual property,” “contract disputes”), then create topic nodes that connect all entities from documents within each category.
This method is interpretable and works well for domains with stable taxonomies.
More sophisticated approaches, such as GraphRAG, use hierarchical community detection algorithms to automatically discover entity clusters at multiple granularities, though these require additional computation.
Press enter or click to view image in full size
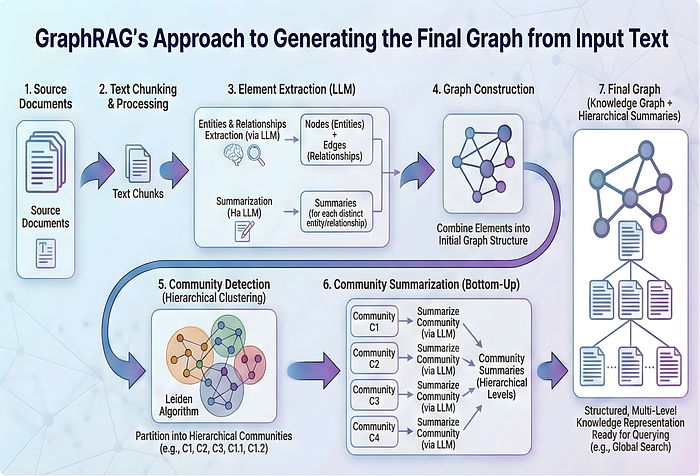
Infographic showing the entire process involved when using GraphRAG to generate the queryable knowledge.
The choice between predefined classification and automated discovery depends on whether your domain has well-established categories or benefits from emergent pattern detection.
Choosing the Right Augmentation Strategy¶
In my legal document work with LangExtract, I found that a straightforward approach proved sufficient: using the same generative model to infer implicit entities and relations from both the ground truth graph and the original text.
This augmentation strategy — constrained to predefined relation types — produced knowledge graphs that effectively captured the semantic structure needed for downstream GNN-based classification tasks.
The optimal augmentation strategy depends entirely on your downstream application. For tasks requiring complex reasoning across disconnected components, clustering techniques provide the necessary connectivity.
For classification or entity-focused tasks, selective inference of implicit knowledge may suffice. For high-stakes domains where correctness trumps coverage, rule-based approaches ensure reliability.
Before augmentation:
“Party A” (entity)
“Employment Contract” (entity)
After adding taxonomic relations:
“Party A” → [is a] → “Corporation” → [is a] → “Legal Entity”
“Employment Contract” → [is a] → “Legal Contract” → [is a] → “Document”
Trial and error reveals that the most effective solution often defies initial intuition — start with your asserted foundation, then iterate on augmentation until the graph serves its intended purpose.
What’s Next: A Practical Framework with Hands-On Code¶
Understanding these augmentation strategies is one thing — implementing them reliably is another. In the next post, I’ll demonstrate a practical approach to automatic knowledge graph augmentation using LangExtract for initial extraction, then iteratively augmenting the asserted graph with the same language model to infer missing entities and relations. All with hands-on code you can run yourself.
The framework addresses the key challenge we’ve discussed: eliminate disconnected components without introducing excessive hallucinations.
Starting with LangExtract’s paragraph-level extraction of the asserted graph, I’ll show how to use the same LLM in an iterative refinement loop — prompting it to identify and fill gaps until the graph achieves full connectivity, all while maintaining traceability back to source text.
While I’ll demonstrate it on legal document analysis from my experiments, the same pattern applies across domains: extract your asserted foundation, then iteratively prompt for missing connections using domain-appropriate constraints.
Whether you’re working with medical records, scientific literature, or business documents, the framework adapts to your needs just by using new prompts for those domains.
What’s your biggest challenge with knowledge graph extraction? Share your experience in the comments, and I’ll address specific questions in the follow-up post with hands-on code.
Follow me for Part 2 next week, where we’ll implement this framework with LangExtract and demonstrate iterative graph augmentation on real legal documents.
Read more on my series using LLMs with graphs:
[## From Rows to Relationships: turn your SQL into a graph.
Most of your data lives in relational databases. Most of your interesting questions live in the connections: who…¶
medium.com](https://medium.com/data-science-collective/from-rows-to-relationships-turn-your-sql-into-a-graph-16436e9832e9?source=post_page-----dcb029f35f5b---------------------------------------)
Understanding should not be a luxury reserved for specialists.
My goal is to make frontier AI and machine learning research accessible through clear, tutorial-style explanations.If this piece helped you think more clearly about the topic, showing support with claps or a subscription genuinely helps keep this work going.
You’re always welcome to connect with me on LinkedIn, where I share more writing and ideas in the same spirit.