Does GraphRAG Really Outperform RAG?¶
Author: Florian June
Published:
Source: https://pub.towardsai.net/does-graphrag-really-outperform-rag-6c1a32c50683
Fetched: 2026-06-07T02:50:28.207776
Does GraphRAG Really Outperform RAG?¶
If you’ve ever asked yourself, “Does GraphRAG really outperform vanilla RAG — and by how much?”, you’re not alone. It’s a question that’s been floating around among devs and researchers alike, especially those working on RAG tasks.
A recent study dives right into this exact question, using a focused and rigorous setup: textbook-level retrieval QA, page by page.
It used the undergraduate math textbook “An Infinite Descent into Pure Mathematics” as their dataset. After OCR processing using the GPT Vision model, they created a custom benchmark of 477 samples, which were manually reviewed and filtered down from an initial set of 628. Each consisting of a question, answer, and the specific textbook page it’s based on.
RAG Settings¶
For the baseline RAG, It tested five popular embedding models (think: voyage-3-large, nvidia/nv-embed-v2, and others). On the other hand, GraphRAG was built to leverage inter-page relationships—essentially modeling how concepts flow across pages to support richer retrieval context.
Press enter or click to view image in full size
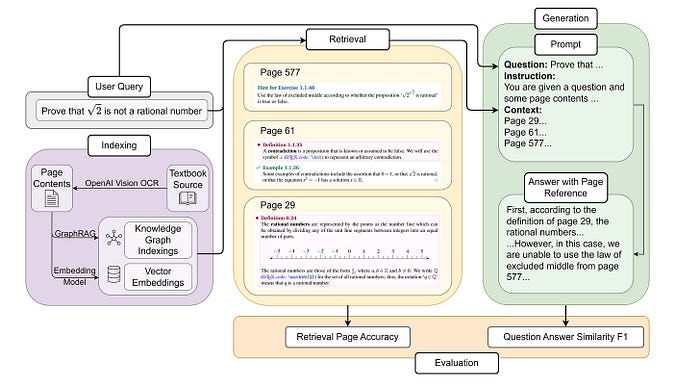
Figure 1: A representative diagram of RAG pipeline. [Source].
Figure 1 is a quick breakdown of how the RAG pipeline works, illustrated through a simple three-step process:
- Indexing. First, the source documents are either embedded into vectors or structured as relational entities when using GraphRAG. This step sets the foundation for everything that follows.
- Retrieval. Given a user query, the system searches for the top-k most relevant pages or entities based on semantic similarity. The goal is to pull in the most useful context to help answer the question.
- Generation. Finally, the model takes in the query, the prompt, and the retrieved content, then generates an answer using a large language model.
GraphRAG Settings¶
The baseline setup follows the GraphRAG pipeline from Microsoft Research. It starts with entity and relation extraction from textbook pages, then builds a knowledge graph, and finally performs graph-based retrieval and generation. Each node in the graph carries its source snippet to keep things traceable.
But this study didn’t stop there. They introduced some key improvements to make the pipeline more transparent and page-aware. Specifically, they explicitly tagged each knowledge entity and text chunk with document_ids and entity_ids, and added parameters like include_document_ids to the context-building functions. This allows every retrieved item to be linked back to its exact page number in the textbook.
Evaluation¶
To evaluate performance, there are two main metrics.
The first is Retrieval Page Accuracy, which measures how often the correct page is successfully retrieved. The second is Question Answer Similarity F1, which looks at the overlap between the model’s output and the ground-truth answer. This is calculated using shared words. Precision captures how much of the output overlaps with the ground truth, while recall measures how much of the ground truth is covered in the output. The F1 score balances both, giving a sense of overall alignment.
Press enter or click to view image in full size
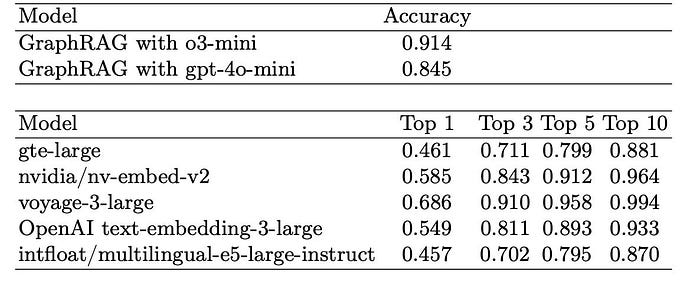
Figure 2: Target Page Retrieval Accuracy for different models. [Source].
Press enter or click to view image in full size
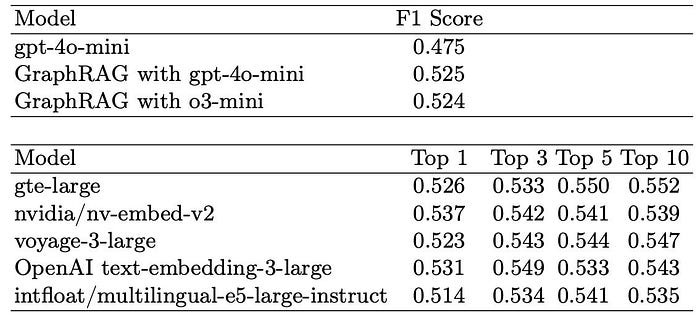
Figure 3: F1 Score for Answer Generation Performance for different models. [Source].
So, how does GraphRAG actually perform?
The results are mixed. In terms of Retrieval Accuracy, it performs very well (achieving 0.914 with o3-mini), comparable to the Top-3 performance of the best RAG models. However, regarding the F1 score for generated answers, it does underperform compared to most RAG setups.
One key issue is redundancy. Because GraphRAG retrieves related entities rather than just the most relevant page, it often pulls in extra content that isn’t directly helpful. This extra noise tends to dilute the quality of the generated answers.
In terms of F1 score, GraphRAG falls behind most of the embedding-based RAG models. The extra context doesn’t always align well with the structure of textbook pages, which makes it harder for the model to stay on target.
The takeaway is pretty clear. For page-level question answering on math textbooks, traditional embedding-based RAG is currently the better choice. GraphRAG still struggles with quality of answer generation and page alignment, which limits its overall effectiveness.
Thoughts¶
I want to share a few thoughts.
The granularity in this task is page-to-page — you ask a question about one page and expect an answer grounded on that same page. But GraphRAG’s graph connects concept-to-concept. That gap matters. A better approach might be to construct a graph of pages, where each node represents a page and edges represent section structure, formula dependencies, or cross-page references. Then, only expand the neighborhood when confidence is low, to reduce noise and manage costs.
In addition, evaluation should go beyond just page hits and F1 scores. In a real textbook setting, what matters more is instructional sufficiency and reference robustness — things like whether nearby pages are meaningfully linked, whether key definitions and formulas are covered, and whether references hold up consistently. These are the metrics that better reflect the true value of retrieval in an educational context.
My Latest Articles: aiexpjourney.substack.com.